한글의 구성
조합가능한 한글의 총 갯수는 11172(= 19 x 21 x 28)개 입니다.
| 종류 | 갯수 | 구성 |
|---|---|---|
| 자음 | 14 | ㄱㄴㄷㄹㅁㅂㅅㅇㅈㅊㅋㅌㅍㅎ |
| 모음 | 10 | ㅏㅑㅓㅕㅗㅛㅜㅠㅡㅣ |
| 겹자음 | 5 | ㄲㄸㅃㅆㅉ |
| 겹받침 | 13 | ㄲㄳㄵㄶㄺㄻㄼㄽㄾㄿㅀㅄㅆ |
| 겹모음 | 11 | ㅐㅒㅔㅖㅘㅙㅚㅝㅞㅟㅢ |
| 위치 | 구성 | 순서(오름차순) |
|---|---|---|
| 초성(19) | 자음(14) + 겹자음(5) | ㄱ ㄲ ㄴ ㄷ ㄸ ㄹ ㅁ ㅂ ㅃ ㅅ ㅆ ㅇ ㅈ ㅉ ㅊ ㅋ ㅌ ㅍ ㅎ |
| 중성(21) | 모음(10) + 겹모음(11) | ㅏ ㅐ ㅑ ㅒ ㅓ ㅔ ㅕ ㅖ ㅗ ㅘ ㅙ ㅚ ㅛ ㅜ ㅝ ㅞ ㅟ ㅠ ㅡ ㅢ ㅣ |
| 종성(28) | 없음(1) + 자음(14) + 겹받침(13) | (x) ㄱ ㄲ ㄳ ㄴ ㄵ ㄶ ㄷ ㄹ ㄺ ㄻ ㄼ ㄽ ㄾ ㄿ ㅀ ㅁ ㅂ ㅄ ㅅ ㅆ ㅇ ㅈ ㅊ ㅋ ㅌ ㅍ ㅎ |
유니코드
유니코드(Unicode)는 문자열 코드의 일종입니다. 유니코드는 전세계 모든 문자를 숫자와 1:1 대응하여 관리합니다. 영문과 일부 기호를 관리하는 코드는 ascii코드입니다.
- 1100—11FF (256): Hangul Jamo
- 3130—318F (96): Hangul Compatibility Jamo
- A960—A97F (32): Hangul Jamo Extended-A
- AC00—D7AF (11184): 한글 음절 Hangul Syllables
- D7B0—D7FF (80): Hangul Jamo Extended-B
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x110 | ᄀ | ᄁ | ᄂ | ᄃ | ᄄ | ᄅ | ᄆ | ᄇ | ᄈ | ᄉ | ᄊ | ᄋ | ᄌ | ᄍ | ᄎ | ᄏ |
| 0x111 | ᄐ | ᄑ | ᄒ | ᄓ | ᄔ | ᄕ | ᄖ | ᄗ | ᄘ | ᄙ | ᄚ | ᄛ | ᄜ | ᄝ | ᄞ | ᄟ |
| 0x112 | ᄠ | ᄡ | ᄢ | ᄣ | ᄤ | ᄥ | ᄦ | ᄧ | ᄨ | ᄩ | ᄪ | ᄫ | ᄬ | ᄭ | ᄮ | ᄯ |
| 0x113 | ᄰ | ᄱ | ᄲ | ᄳ | ᄴ | ᄵ | ᄶ | ᄷ | ᄸ | ᄹ | ᄺ | ᄻ | ᄼ | ᄽ | ᄾ | ᄿ |
| 0x114 | ᅀ | ᅁ | ᅂ | ᅃ | ᅄ | ᅅ | ᅆ | ᅇ | ᅈ | ᅉ | ᅊ | ᅋ | ᅌ | ᅍ | ᅎ | ᅏ |
| 0x115 | ᅐ | ᅑ | ᅒ | ᅓ | ᅔ | ᅕ | ᅖ | ᅗ | ᅘ | ᅙ | ᅚ | ᅛ | ᅜ | ᅝ | ᅞ | ᅟ |
| 0x116 | ᅠ | ᅡ | ᅢ | ᅣ | ᅤ | ᅥ | ᅦ | ᅧ | ᅨ | ᅩ | ᅪ | ᅫ | ᅬ | ᅭ | ᅮ | ᅯ |
| 0x117 | ᅰ | ᅱ | ᅲ | ᅳ | ᅴ | ᅵ | ᅶ | ᅷ | ᅸ | ᅹ | ᅺ | ᅻ | ᅼ | ᅽ | ᅾ | ᅿ |
| 0x118 | ᆀ | ᆁ | ᆂ | ᆃ | ᆄ | ᆅ | ᆆ | ᆇ | ᆈ | ᆉ | ᆊ | ᆋ | ᆌ | ᆍ | ᆎ | ᆏ |
| 0x119 | ᆐ | ᆑ | ᆒ | ᆓ | ᆔ | ᆕ | ᆖ | ᆗ | ᆘ | ᆙ | ᆚ | ᆛ | ᆜ | ᆝ | ᆞ | ᆟ |
| 0x11a | ᆠ | ᆡ | ᆢ | ᆣ | ᆤ | ᆥ | ᆦ | ᆧ | ᆨ | ᆩ | ᆪ | ᆫ | ᆬ | ᆭ | ᆮ | ᆯ |
| 0x11b | ᆰ | ᆱ | ᆲ | ᆳ | ᆴ | ᆵ | ᆶ | ᆷ | ᆸ | ᆹ | ᆺ | ᆻ | ᆼ | ᆽ | ᆾ | ᆿ |
| 0x11c | ᇀ | ᇁ | ᇂ | ᇃ | ᇄ | ᇅ | ᇆ | ᇇ | ᇈ | ᇉ | ᇊ | ᇋ | ᇌ | ᇍ | ᇎ | ᇏ |
| 0x11d | ᇐ | ᇑ | ᇒ | ᇓ | ᇔ | ᇕ | ᇖ | ᇗ | ᇘ | ᇙ | ᇚ | ᇛ | ᇜ | ᇝ | ᇞ | ᇟ |
| 0x11e | ᇠ | ᇡ | ᇢ | ᇣ | ᇤ | ᇥ | ᇦ | ᇧ | ᇨ | ᇩ | ᇪ | ᇫ | ᇬ | ᇭ | ᇮ | ᇯ |
| 0x11f | ᇰ | ᇱ | ᇲ | ᇳ | ᇴ | ᇵ | ᇶ | ᇷ | ᇸ | ᇹ | ᇺ | ᇻ | ᇼ | ᇽ | ᇾ | ᇿ |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x313 | | ㄱ | ㄲ | ㄳ | ㄴ | ㄵ | ㄶ | ㄷ | ㄸ | ㄹ | ㄺ | ㄻ | ㄼ | ㄽ | ㄾ | ㄿ |
| 0x314 | ㅀ | ㅁ | ㅂ | ㅃ | ㅄ | ㅅ | ㅆ | ㅇ | ㅈ | ㅉ | ㅊ | ㅋ | ㅌ | ㅍ | ㅎ | ㅏ |
| 0x315 | ㅐ | ㅑ | ㅒ | ㅓ | ㅔ | ㅕ | ㅖ | ㅗ | ㅘ | ㅙ | ㅚ | ㅛ | ㅜ | ㅝ | ㅞ | ㅟ |
| 0x316 | ㅠ | ㅡ | ㅢ | ㅣ | ㅤ | ㅥ | ㅦ | ㅧ | ㅨ | ㅩ | ㅪ | ㅫ | ㅬ | ㅭ | ㅮ | ㅯ |
| 0x317 | ㅰ | ㅱ | ㅲ | ㅳ | ㅴ | ㅵ | ㅶ | ㅷ | ㅸ | ㅹ | ㅺ | ㅻ | ㅼ | ㅽ | ㅾ | ㅿ |
| 0x318 | ㆀ | ㆁ | ㆂ | ㆃ | ㆄ | ㆅ | ㆆ | ㆇ | ㆈ | ㆉ | ㆊ | ㆋ | ㆌ | ㆍ | ㆎ | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xa96 | ꥠ | ꥡ | ꥢ | ꥣ | ꥤ | ꥥ | ꥦ | ꥧ | ꥨ | ꥩ | ꥪ | ꥫ | ꥬ | ꥭ | ꥮ | ꥯ |
| 0xa97 | ꥰ | ꥱ | ꥲ | ꥳ | ꥴ | ꥵ | ꥶ | ꥷ | ꥸ | ꥹ | ꥺ | ꥻ | ꥼ | | | |
Hangul Syllables(11172글자) 열기(테이블이 너무 큽니다.)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xac0 | 가 | 각 | 갂 | 갃 | 간 | 갅 | 갆 | 갇 | 갈 | 갉 | 갊 | 갋 | 갌 | 갍 | 갎 | 갏 |
| 0xac1 | 감 | 갑 | 값 | 갓 | 갔 | 강 | 갖 | 갗 | 갘 | 같 | 갚 | 갛 | 개 | 객 | 갞 | 갟 |
| 0xac2 | 갠 | 갡 | 갢 | 갣 | 갤 | 갥 | 갦 | 갧 | 갨 | 갩 | 갪 | 갫 | 갬 | 갭 | 갮 | 갯 |
| 0xac3 | 갰 | 갱 | 갲 | 갳 | 갴 | 갵 | 갶 | 갷 | 갸 | 갹 | 갺 | 갻 | 갼 | 갽 | 갾 | 갿 |
| 0xac4 | 걀 | 걁 | 걂 | 걃 | 걄 | 걅 | 걆 | 걇 | 걈 | 걉 | 걊 | 걋 | 걌 | 걍 | 걎 | 걏 |
| 0xac5 | 걐 | 걑 | 걒 | 걓 | 걔 | 걕 | 걖 | 걗 | 걘 | 걙 | 걚 | 걛 | 걜 | 걝 | 걞 | 걟 |
| 0xac6 | 걠 | 걡 | 걢 | 걣 | 걤 | 걥 | 걦 | 걧 | 걨 | 걩 | 걪 | 걫 | 걬 | 걭 | 걮 | 걯 |
| 0xac7 | 거 | 걱 | 걲 | 걳 | 건 | 걵 | 걶 | 걷 | 걸 | 걹 | 걺 | 걻 | 걼 | 걽 | 걾 | 걿 |
| 0xac8 | 검 | 겁 | 겂 | 것 | 겄 | 겅 | 겆 | 겇 | 겈 | 겉 | 겊 | 겋 | 게 | 겍 | 겎 | 겏 |
| 0xac9 | 겐 | 겑 | 겒 | 겓 | 겔 | 겕 | 겖 | 겗 | 겘 | 겙 | 겚 | 겛 | 겜 | 겝 | 겞 | 겟 |
| 0xaca | 겠 | 겡 | 겢 | 겣 | 겤 | 겥 | 겦 | 겧 | 겨 | 격 | 겪 | 겫 | 견 | 겭 | 겮 | 겯 |
| 0xacb | 결 | 겱 | 겲 | 겳 | 겴 | 겵 | 겶 | 겷 | 겸 | 겹 | 겺 | 겻 | 겼 | 경 | 겾 | 겿 |
| 0xacc | 곀 | 곁 | 곂 | 곃 | 계 | 곅 | 곆 | 곇 | 곈 | 곉 | 곊 | 곋 | 곌 | 곍 | 곎 | 곏 |
| 0xacd | 곐 | 곑 | 곒 | 곓 | 곔 | 곕 | 곖 | 곗 | 곘 | 곙 | 곚 | 곛 | 곜 | 곝 | 곞 | 곟 |
| 0xace | 고 | 곡 | 곢 | 곣 | 곤 | 곥 | 곦 | 곧 | 골 | 곩 | 곪 | 곫 | 곬 | 곭 | 곮 | 곯 |
| 0xacf | 곰 | 곱 | 곲 | 곳 | 곴 | 공 | 곶 | 곷 | 곸 | 곹 | 곺 | 곻 | 과 | 곽 | 곾 | 곿 |
| 0xad0 | 관 | 괁 | 괂 | 괃 | 괄 | 괅 | 괆 | 괇 | 괈 | 괉 | 괊 | 괋 | 괌 | 괍 | 괎 | 괏 |
| 0xad1 | 괐 | 광 | 괒 | 괓 | 괔 | 괕 | 괖 | 괗 | 괘 | 괙 | 괚 | 괛 | 괜 | 괝 | 괞 | 괟 |
| 0xad2 | 괠 | 괡 | 괢 | 괣 | 괤 | 괥 | 괦 | 괧 | 괨 | 괩 | 괪 | 괫 | 괬 | 괭 | 괮 | 괯 |
| 0xad3 | 괰 | 괱 | 괲 | 괳 | 괴 | 괵 | 괶 | 괷 | 괸 | 괹 | 괺 | 괻 | 괼 | 괽 | 괾 | 괿 |
| 0xad4 | 굀 | 굁 | 굂 | 굃 | 굄 | 굅 | 굆 | 굇 | 굈 | 굉 | 굊 | 굋 | 굌 | 굍 | 굎 | 굏 |
| 0xad5 | 교 | 굑 | 굒 | 굓 | 굔 | 굕 | 굖 | 굗 | 굘 | 굙 | 굚 | 굛 | 굜 | 굝 | 굞 | 굟 |
| 0xad6 | 굠 | 굡 | 굢 | 굣 | 굤 | 굥 | 굦 | 굧 | 굨 | 굩 | 굪 | 굫 | 구 | 국 | 굮 | 굯 |
| 0xad7 | 군 | 굱 | 굲 | 굳 | 굴 | 굵 | 굶 | 굷 | 굸 | 굹 | 굺 | 굻 | 굼 | 굽 | 굾 | 굿 |
| 0xad8 | 궀 | 궁 | 궂 | 궃 | 궄 | 궅 | 궆 | 궇 | 궈 | 궉 | 궊 | 궋 | 권 | 궍 | 궎 | 궏 |
| 0xad9 | 궐 | 궑 | 궒 | 궓 | 궔 | 궕 | 궖 | 궗 | 궘 | 궙 | 궚 | 궛 | 궜 | 궝 | 궞 | 궟 |
| 0xada | 궠 | 궡 | 궢 | 궣 | 궤 | 궥 | 궦 | 궧 | 궨 | 궩 | 궪 | 궫 | 궬 | 궭 | 궮 | 궯 |
| 0xadb | 궰 | 궱 | 궲 | 궳 | 궴 | 궵 | 궶 | 궷 | 궸 | 궹 | 궺 | 궻 | 궼 | 궽 | 궾 | 궿 |
| 0xadc | 귀 | 귁 | 귂 | 귃 | 귄 | 귅 | 귆 | 귇 | 귈 | 귉 | 귊 | 귋 | 귌 | 귍 | 귎 | 귏 |
| 0xadd | 귐 | 귑 | 귒 | 귓 | 귔 | 귕 | 귖 | 귗 | 귘 | 귙 | 귚 | 귛 | 규 | 귝 | 귞 | 귟 |
| 0xade | 균 | 귡 | 귢 | 귣 | 귤 | 귥 | 귦 | 귧 | 귨 | 귩 | 귪 | 귫 | 귬 | 귭 | 귮 | 귯 |
| 0xadf | 귰 | 귱 | 귲 | 귳 | 귴 | 귵 | 귶 | 귷 | 그 | 극 | 귺 | 귻 | 근 | 귽 | 귾 | 귿 |
| 0xae0 | 글 | 긁 | 긂 | 긃 | 긄 | 긅 | 긆 | 긇 | 금 | 급 | 긊 | 긋 | 긌 | 긍 | 긎 | 긏 |
| 0xae1 | 긐 | 긑 | 긒 | 긓 | 긔 | 긕 | 긖 | 긗 | 긘 | 긙 | 긚 | 긛 | 긜 | 긝 | 긞 | 긟 |
| 0xae2 | 긠 | 긡 | 긢 | 긣 | 긤 | 긥 | 긦 | 긧 | 긨 | 긩 | 긪 | 긫 | 긬 | 긭 | 긮 | 긯 |
| 0xae3 | 기 | 긱 | 긲 | 긳 | 긴 | 긵 | 긶 | 긷 | 길 | 긹 | 긺 | 긻 | 긼 | 긽 | 긾 | 긿 |
| 0xae4 | 김 | 깁 | 깂 | 깃 | 깄 | 깅 | 깆 | 깇 | 깈 | 깉 | 깊 | 깋 | 까 | 깍 | 깎 | 깏 |
| 0xae5 | 깐 | 깑 | 깒 | 깓 | 깔 | 깕 | 깖 | 깗 | 깘 | 깙 | 깚 | 깛 | 깜 | 깝 | 깞 | 깟 |
| 0xae6 | 깠 | 깡 | 깢 | 깣 | 깤 | 깥 | 깦 | 깧 | 깨 | 깩 | 깪 | 깫 | 깬 | 깭 | 깮 | 깯 |
| 0xae7 | 깰 | 깱 | 깲 | 깳 | 깴 | 깵 | 깶 | 깷 | 깸 | 깹 | 깺 | 깻 | 깼 | 깽 | 깾 | 깿 |
| 0xae8 | 꺀 | 꺁 | 꺂 | 꺃 | 꺄 | 꺅 | 꺆 | 꺇 | 꺈 | 꺉 | 꺊 | 꺋 | 꺌 | 꺍 | 꺎 | 꺏 |
| 0xae9 | 꺐 | 꺑 | 꺒 | 꺓 | 꺔 | 꺕 | 꺖 | 꺗 | 꺘 | 꺙 | 꺚 | 꺛 | 꺜 | 꺝 | 꺞 | 꺟 |
| 0xaea | 꺠 | 꺡 | 꺢 | 꺣 | 꺤 | 꺥 | 꺦 | 꺧 | 꺨 | 꺩 | 꺪 | 꺫 | 꺬 | 꺭 | 꺮 | 꺯 |
| 0xaeb | 꺰 | 꺱 | 꺲 | 꺳 | 꺴 | 꺵 | 꺶 | 꺷 | 꺸 | 꺹 | 꺺 | 꺻 | 꺼 | 꺽 | 꺾 | 꺿 |
| 0xaec | 껀 | 껁 | 껂 | 껃 | 껄 | 껅 | 껆 | 껇 | 껈 | 껉 | 껊 | 껋 | 껌 | 껍 | 껎 | 껏 |
| 0xaed | 껐 | 껑 | 껒 | 껓 | 껔 | 껕 | 껖 | 껗 | 께 | 껙 | 껚 | 껛 | 껜 | 껝 | 껞 | 껟 |
| 0xaee | 껠 | 껡 | 껢 | 껣 | 껤 | 껥 | 껦 | 껧 | 껨 | 껩 | 껪 | 껫 | 껬 | 껭 | 껮 | 껯 |
| 0xaef | 껰 | 껱 | 껲 | 껳 | 껴 | 껵 | 껶 | 껷 | 껸 | 껹 | 껺 | 껻 | 껼 | 껽 | 껾 | 껿 |
| 0xaf0 | 꼀 | 꼁 | 꼂 | 꼃 | 꼄 | 꼅 | 꼆 | 꼇 | 꼈 | 꼉 | 꼊 | 꼋 | 꼌 | 꼍 | 꼎 | 꼏 |
| 0xaf1 | 꼐 | 꼑 | 꼒 | 꼓 | 꼔 | 꼕 | 꼖 | 꼗 | 꼘 | 꼙 | 꼚 | 꼛 | 꼜 | 꼝 | 꼞 | 꼟 |
| 0xaf2 | 꼠 | 꼡 | 꼢 | 꼣 | 꼤 | 꼥 | 꼦 | 꼧 | 꼨 | 꼩 | 꼪 | 꼫 | 꼬 | 꼭 | 꼮 | 꼯 |
| 0xaf3 | 꼰 | 꼱 | 꼲 | 꼳 | 꼴 | 꼵 | 꼶 | 꼷 | 꼸 | 꼹 | 꼺 | 꼻 | 꼼 | 꼽 | 꼾 | 꼿 |
| 0xaf4 | 꽀 | 꽁 | 꽂 | 꽃 | 꽄 | 꽅 | 꽆 | 꽇 | 꽈 | 꽉 | 꽊 | 꽋 | 꽌 | 꽍 | 꽎 | 꽏 |
| 0xaf5 | 꽐 | 꽑 | 꽒 | 꽓 | 꽔 | 꽕 | 꽖 | 꽗 | 꽘 | 꽙 | 꽚 | 꽛 | 꽜 | 꽝 | 꽞 | 꽟 |
| 0xaf6 | 꽠 | 꽡 | 꽢 | 꽣 | 꽤 | 꽥 | 꽦 | 꽧 | 꽨 | 꽩 | 꽪 | 꽫 | 꽬 | 꽭 | 꽮 | 꽯 |
| 0xaf7 | 꽰 | 꽱 | 꽲 | 꽳 | 꽴 | 꽵 | 꽶 | 꽷 | 꽸 | 꽹 | 꽺 | 꽻 | 꽼 | 꽽 | 꽾 | 꽿 |
| 0xaf8 | 꾀 | 꾁 | 꾂 | 꾃 | 꾄 | 꾅 | 꾆 | 꾇 | 꾈 | 꾉 | 꾊 | 꾋 | 꾌 | 꾍 | 꾎 | 꾏 |
| 0xaf9 | 꾐 | 꾑 | 꾒 | 꾓 | 꾔 | 꾕 | 꾖 | 꾗 | 꾘 | 꾙 | 꾚 | 꾛 | 꾜 | 꾝 | 꾞 | 꾟 |
| 0xafa | 꾠 | 꾡 | 꾢 | 꾣 | 꾤 | 꾥 | 꾦 | 꾧 | 꾨 | 꾩 | 꾪 | 꾫 | 꾬 | 꾭 | 꾮 | 꾯 |
| 0xafb | 꾰 | 꾱 | 꾲 | 꾳 | 꾴 | 꾵 | 꾶 | 꾷 | 꾸 | 꾹 | 꾺 | 꾻 | 꾼 | 꾽 | 꾾 | 꾿 |
| 0xafc | 꿀 | 꿁 | 꿂 | 꿃 | 꿄 | 꿅 | 꿆 | 꿇 | 꿈 | 꿉 | 꿊 | 꿋 | 꿌 | 꿍 | 꿎 | 꿏 |
| 0xafd | 꿐 | 꿑 | 꿒 | 꿓 | 꿔 | 꿕 | 꿖 | 꿗 | 꿘 | 꿙 | 꿚 | 꿛 | 꿜 | 꿝 | 꿞 | 꿟 |
| 0xafe | 꿠 | 꿡 | 꿢 | 꿣 | 꿤 | 꿥 | 꿦 | 꿧 | 꿨 | 꿩 | 꿪 | 꿫 | 꿬 | 꿭 | 꿮 | 꿯 |
| 0xaff | 꿰 | 꿱 | 꿲 | 꿳 | 꿴 | 꿵 | 꿶 | 꿷 | 꿸 | 꿹 | 꿺 | 꿻 | 꿼 | 꿽 | 꿾 | 꿿 |
| 0xb00 | 뀀 | 뀁 | 뀂 | 뀃 | 뀄 | 뀅 | 뀆 | 뀇 | 뀈 | 뀉 | 뀊 | 뀋 | 뀌 | 뀍 | 뀎 | 뀏 |
| 0xb01 | 뀐 | 뀑 | 뀒 | 뀓 | 뀔 | 뀕 | 뀖 | 뀗 | 뀘 | 뀙 | 뀚 | 뀛 | 뀜 | 뀝 | 뀞 | 뀟 |
| 0xb02 | 뀠 | 뀡 | 뀢 | 뀣 | 뀤 | 뀥 | 뀦 | 뀧 | 뀨 | 뀩 | 뀪 | 뀫 | 뀬 | 뀭 | 뀮 | 뀯 |
| 0xb03 | 뀰 | 뀱 | 뀲 | 뀳 | 뀴 | 뀵 | 뀶 | 뀷 | 뀸 | 뀹 | 뀺 | 뀻 | 뀼 | 뀽 | 뀾 | 뀿 |
| 0xb04 | 끀 | 끁 | 끂 | 끃 | 끄 | 끅 | 끆 | 끇 | 끈 | 끉 | 끊 | 끋 | 끌 | 끍 | 끎 | 끏 |
| 0xb05 | 끐 | 끑 | 끒 | 끓 | 끔 | 끕 | 끖 | 끗 | 끘 | 끙 | 끚 | 끛 | 끜 | 끝 | 끞 | 끟 |
| 0xb06 | 끠 | 끡 | 끢 | 끣 | 끤 | 끥 | 끦 | 끧 | 끨 | 끩 | 끪 | 끫 | 끬 | 끭 | 끮 | 끯 |
| 0xb07 | 끰 | 끱 | 끲 | 끳 | 끴 | 끵 | 끶 | 끷 | 끸 | 끹 | 끺 | 끻 | 끼 | 끽 | 끾 | 끿 |
| 0xb08 | 낀 | 낁 | 낂 | 낃 | 낄 | 낅 | 낆 | 낇 | 낈 | 낉 | 낊 | 낋 | 낌 | 낍 | 낎 | 낏 |
| 0xb09 | 낐 | 낑 | 낒 | 낓 | 낔 | 낕 | 낖 | 낗 | 나 | 낙 | 낚 | 낛 | 난 | 낝 | 낞 | 낟 |
| 0xb0a | 날 | 낡 | 낢 | 낣 | 낤 | 낥 | 낦 | 낧 | 남 | 납 | 낪 | 낫 | 났 | 낭 | 낮 | 낯 |
| 0xb0b | 낰 | 낱 | 낲 | 낳 | 내 | 낵 | 낶 | 낷 | 낸 | 낹 | 낺 | 낻 | 낼 | 낽 | 낾 | 낿 |
| 0xb0c | 냀 | 냁 | 냂 | 냃 | 냄 | 냅 | 냆 | 냇 | 냈 | 냉 | 냊 | 냋 | 냌 | 냍 | 냎 | 냏 |
| 0xb0d | 냐 | 냑 | 냒 | 냓 | 냔 | 냕 | 냖 | 냗 | 냘 | 냙 | 냚 | 냛 | 냜 | 냝 | 냞 | 냟 |
| 0xb0e | 냠 | 냡 | 냢 | 냣 | 냤 | 냥 | 냦 | 냧 | 냨 | 냩 | 냪 | 냫 | 냬 | 냭 | 냮 | 냯 |
| 0xb0f | 냰 | 냱 | 냲 | 냳 | 냴 | 냵 | 냶 | 냷 | 냸 | 냹 | 냺 | 냻 | 냼 | 냽 | 냾 | 냿 |
| 0xb10 | 넀 | 넁 | 넂 | 넃 | 넄 | 넅 | 넆 | 넇 | 너 | 넉 | 넊 | 넋 | 넌 | 넍 | 넎 | 넏 |
| 0xb11 | 널 | 넑 | 넒 | 넓 | 넔 | 넕 | 넖 | 넗 | 넘 | 넙 | 넚 | 넛 | 넜 | 넝 | 넞 | 넟 |
| 0xb12 | 넠 | 넡 | 넢 | 넣 | 네 | 넥 | 넦 | 넧 | 넨 | 넩 | 넪 | 넫 | 넬 | 넭 | 넮 | 넯 |
| 0xb13 | 넰 | 넱 | 넲 | 넳 | 넴 | 넵 | 넶 | 넷 | 넸 | 넹 | 넺 | 넻 | 넼 | 넽 | 넾 | 넿 |
| 0xb14 | 녀 | 녁 | 녂 | 녃 | 년 | 녅 | 녆 | 녇 | 녈 | 녉 | 녊 | 녋 | 녌 | 녍 | 녎 | 녏 |
| 0xb15 | 념 | 녑 | 녒 | 녓 | 녔 | 녕 | 녖 | 녗 | 녘 | 녙 | 녚 | 녛 | 녜 | 녝 | 녞 | 녟 |
| 0xb16 | 녠 | 녡 | 녢 | 녣 | 녤 | 녥 | 녦 | 녧 | 녨 | 녩 | 녪 | 녫 | 녬 | 녭 | 녮 | 녯 |
| 0xb17 | 녰 | 녱 | 녲 | 녳 | 녴 | 녵 | 녶 | 녷 | 노 | 녹 | 녺 | 녻 | 논 | 녽 | 녾 | 녿 |
| 0xb18 | 놀 | 놁 | 놂 | 놃 | 놄 | 놅 | 놆 | 놇 | 놈 | 놉 | 놊 | 놋 | 놌 | 농 | 놎 | 놏 |
| 0xb19 | 놐 | 놑 | 높 | 놓 | 놔 | 놕 | 놖 | 놗 | 놘 | 놙 | 놚 | 놛 | 놜 | 놝 | 놞 | 놟 |
| 0xb1a | 놠 | 놡 | 놢 | 놣 | 놤 | 놥 | 놦 | 놧 | 놨 | 놩 | 놪 | 놫 | 놬 | 놭 | 놮 | 놯 |
| 0xb1b | 놰 | 놱 | 놲 | 놳 | 놴 | 놵 | 놶 | 놷 | 놸 | 놹 | 놺 | 놻 | 놼 | 놽 | 놾 | 놿 |
| 0xb1c | 뇀 | 뇁 | 뇂 | 뇃 | 뇄 | 뇅 | 뇆 | 뇇 | 뇈 | 뇉 | 뇊 | 뇋 | 뇌 | 뇍 | 뇎 | 뇏 |
| 0xb1d | 뇐 | 뇑 | 뇒 | 뇓 | 뇔 | 뇕 | 뇖 | 뇗 | 뇘 | 뇙 | 뇚 | 뇛 | 뇜 | 뇝 | 뇞 | 뇟 |
| 0xb1e | 뇠 | 뇡 | 뇢 | 뇣 | 뇤 | 뇥 | 뇦 | 뇧 | 뇨 | 뇩 | 뇪 | 뇫 | 뇬 | 뇭 | 뇮 | 뇯 |
| 0xb1f | 뇰 | 뇱 | 뇲 | 뇳 | 뇴 | 뇵 | 뇶 | 뇷 | 뇸 | 뇹 | 뇺 | 뇻 | 뇼 | 뇽 | 뇾 | 뇿 |
| 0xb20 | 눀 | 눁 | 눂 | 눃 | 누 | 눅 | 눆 | 눇 | 눈 | 눉 | 눊 | 눋 | 눌 | 눍 | 눎 | 눏 |
| 0xb21 | 눐 | 눑 | 눒 | 눓 | 눔 | 눕 | 눖 | 눗 | 눘 | 눙 | 눚 | 눛 | 눜 | 눝 | 눞 | 눟 |
| 0xb22 | 눠 | 눡 | 눢 | 눣 | 눤 | 눥 | 눦 | 눧 | 눨 | 눩 | 눪 | 눫 | 눬 | 눭 | 눮 | 눯 |
| 0xb23 | 눰 | 눱 | 눲 | 눳 | 눴 | 눵 | 눶 | 눷 | 눸 | 눹 | 눺 | 눻 | 눼 | 눽 | 눾 | 눿 |
| 0xb24 | 뉀 | 뉁 | 뉂 | 뉃 | 뉄 | 뉅 | 뉆 | 뉇 | 뉈 | 뉉 | 뉊 | 뉋 | 뉌 | 뉍 | 뉎 | 뉏 |
| 0xb25 | 뉐 | 뉑 | 뉒 | 뉓 | 뉔 | 뉕 | 뉖 | 뉗 | 뉘 | 뉙 | 뉚 | 뉛 | 뉜 | 뉝 | 뉞 | 뉟 |
| 0xb26 | 뉠 | 뉡 | 뉢 | 뉣 | 뉤 | 뉥 | 뉦 | 뉧 | 뉨 | 뉩 | 뉪 | 뉫 | 뉬 | 뉭 | 뉮 | 뉯 |
| 0xb27 | 뉰 | 뉱 | 뉲 | 뉳 | 뉴 | 뉵 | 뉶 | 뉷 | 뉸 | 뉹 | 뉺 | 뉻 | 뉼 | 뉽 | 뉾 | 뉿 |
| 0xb28 | 늀 | 늁 | 늂 | 늃 | 늄 | 늅 | 늆 | 늇 | 늈 | 늉 | 늊 | 늋 | 늌 | 늍 | 늎 | 늏 |
| 0xb29 | 느 | 늑 | 늒 | 늓 | 는 | 늕 | 늖 | 늗 | 늘 | 늙 | 늚 | 늛 | 늜 | 늝 | 늞 | 늟 |
| 0xb2a | 늠 | 늡 | 늢 | 늣 | 늤 | 능 | 늦 | 늧 | 늨 | 늩 | 늪 | 늫 | 늬 | 늭 | 늮 | 늯 |
| 0xb2b | 늰 | 늱 | 늲 | 늳 | 늴 | 늵 | 늶 | 늷 | 늸 | 늹 | 늺 | 늻 | 늼 | 늽 | 늾 | 늿 |
| 0xb2c | 닀 | 닁 | 닂 | 닃 | 닄 | 닅 | 닆 | 닇 | 니 | 닉 | 닊 | 닋 | 닌 | 닍 | 닎 | 닏 |
| 0xb2d | 닐 | 닑 | 닒 | 닓 | 닔 | 닕 | 닖 | 닗 | 님 | 닙 | 닚 | 닛 | 닜 | 닝 | 닞 | 닟 |
| 0xb2e | 닠 | 닡 | 닢 | 닣 | 다 | 닥 | 닦 | 닧 | 단 | 닩 | 닪 | 닫 | 달 | 닭 | 닮 | 닯 |
| 0xb2f | 닰 | 닱 | 닲 | 닳 | 담 | 답 | 닶 | 닷 | 닸 | 당 | 닺 | 닻 | 닼 | 닽 | 닾 | 닿 |
| 0xb30 | 대 | 댁 | 댂 | 댃 | 댄 | 댅 | 댆 | 댇 | 댈 | 댉 | 댊 | 댋 | 댌 | 댍 | 댎 | 댏 |
| 0xb31 | 댐 | 댑 | 댒 | 댓 | 댔 | 댕 | 댖 | 댗 | 댘 | 댙 | 댚 | 댛 | 댜 | 댝 | 댞 | 댟 |
| 0xb32 | 댠 | 댡 | 댢 | 댣 | 댤 | 댥 | 댦 | 댧 | 댨 | 댩 | 댪 | 댫 | 댬 | 댭 | 댮 | 댯 |
| 0xb33 | 댰 | 댱 | 댲 | 댳 | 댴 | 댵 | 댶 | 댷 | 댸 | 댹 | 댺 | 댻 | 댼 | 댽 | 댾 | 댿 |
| 0xb34 | 덀 | 덁 | 덂 | 덃 | 덄 | 덅 | 덆 | 덇 | 덈 | 덉 | 덊 | 덋 | 덌 | 덍 | 덎 | 덏 |
| 0xb35 | 덐 | 덑 | 덒 | 덓 | 더 | 덕 | 덖 | 덗 | 던 | 덙 | 덚 | 덛 | 덜 | 덝 | 덞 | 덟 |
| 0xb36 | 덠 | 덡 | 덢 | 덣 | 덤 | 덥 | 덦 | 덧 | 덨 | 덩 | 덪 | 덫 | 덬 | 덭 | 덮 | 덯 |
| 0xb37 | 데 | 덱 | 덲 | 덳 | 덴 | 덵 | 덶 | 덷 | 델 | 덹 | 덺 | 덻 | 덼 | 덽 | 덾 | 덿 |
| 0xb38 | 뎀 | 뎁 | 뎂 | 뎃 | 뎄 | 뎅 | 뎆 | 뎇 | 뎈 | 뎉 | 뎊 | 뎋 | 뎌 | 뎍 | 뎎 | 뎏 |
| 0xb39 | 뎐 | 뎑 | 뎒 | 뎓 | 뎔 | 뎕 | 뎖 | 뎗 | 뎘 | 뎙 | 뎚 | 뎛 | 뎜 | 뎝 | 뎞 | 뎟 |
| 0xb3a | 뎠 | 뎡 | 뎢 | 뎣 | 뎤 | 뎥 | 뎦 | 뎧 | 뎨 | 뎩 | 뎪 | 뎫 | 뎬 | 뎭 | 뎮 | 뎯 |
| 0xb3b | 뎰 | 뎱 | 뎲 | 뎳 | 뎴 | 뎵 | 뎶 | 뎷 | 뎸 | 뎹 | 뎺 | 뎻 | 뎼 | 뎽 | 뎾 | 뎿 |
| 0xb3c | 돀 | 돁 | 돂 | 돃 | 도 | 독 | 돆 | 돇 | 돈 | 돉 | 돊 | 돋 | 돌 | 돍 | 돎 | 돏 |
| 0xb3d | 돐 | 돑 | 돒 | 돓 | 돔 | 돕 | 돖 | 돗 | 돘 | 동 | 돚 | 돛 | 돜 | 돝 | 돞 | 돟 |
| 0xb3e | 돠 | 돡 | 돢 | 돣 | 돤 | 돥 | 돦 | 돧 | 돨 | 돩 | 돪 | 돫 | 돬 | 돭 | 돮 | 돯 |
| 0xb3f | 돰 | 돱 | 돲 | 돳 | 돴 | 돵 | 돶 | 돷 | 돸 | 돹 | 돺 | 돻 | 돼 | 돽 | 돾 | 돿 |
| 0xb40 | 됀 | 됁 | 됂 | 됃 | 됄 | 됅 | 됆 | 됇 | 됈 | 됉 | 됊 | 됋 | 됌 | 됍 | 됎 | 됏 |
| 0xb41 | 됐 | 됑 | 됒 | 됓 | 됔 | 됕 | 됖 | 됗 | 되 | 됙 | 됚 | 됛 | 된 | 됝 | 됞 | 됟 |
| 0xb42 | 될 | 됡 | 됢 | 됣 | 됤 | 됥 | 됦 | 됧 | 됨 | 됩 | 됪 | 됫 | 됬 | 됭 | 됮 | 됯 |
| 0xb43 | 됰 | 됱 | 됲 | 됳 | 됴 | 됵 | 됶 | 됷 | 됸 | 됹 | 됺 | 됻 | 됼 | 됽 | 됾 | 됿 |
| 0xb44 | 둀 | 둁 | 둂 | 둃 | 둄 | 둅 | 둆 | 둇 | 둈 | 둉 | 둊 | 둋 | 둌 | 둍 | 둎 | 둏 |
| 0xb45 | 두 | 둑 | 둒 | 둓 | 둔 | 둕 | 둖 | 둗 | 둘 | 둙 | 둚 | 둛 | 둜 | 둝 | 둞 | 둟 |
| 0xb46 | 둠 | 둡 | 둢 | 둣 | 둤 | 둥 | 둦 | 둧 | 둨 | 둩 | 둪 | 둫 | 둬 | 둭 | 둮 | 둯 |
| 0xb47 | 둰 | 둱 | 둲 | 둳 | 둴 | 둵 | 둶 | 둷 | 둸 | 둹 | 둺 | 둻 | 둼 | 둽 | 둾 | 둿 |
| 0xb48 | 뒀 | 뒁 | 뒂 | 뒃 | 뒄 | 뒅 | 뒆 | 뒇 | 뒈 | 뒉 | 뒊 | 뒋 | 뒌 | 뒍 | 뒎 | 뒏 |
| 0xb49 | 뒐 | 뒑 | 뒒 | 뒓 | 뒔 | 뒕 | 뒖 | 뒗 | 뒘 | 뒙 | 뒚 | 뒛 | 뒜 | 뒝 | 뒞 | 뒟 |
| 0xb4a | 뒠 | 뒡 | 뒢 | 뒣 | 뒤 | 뒥 | 뒦 | 뒧 | 뒨 | 뒩 | 뒪 | 뒫 | 뒬 | 뒭 | 뒮 | 뒯 |
| 0xb4b | 뒰 | 뒱 | 뒲 | 뒳 | 뒴 | 뒵 | 뒶 | 뒷 | 뒸 | 뒹 | 뒺 | 뒻 | 뒼 | 뒽 | 뒾 | 뒿 |
| 0xb4c | 듀 | 듁 | 듂 | 듃 | 듄 | 듅 | 듆 | 듇 | 듈 | 듉 | 듊 | 듋 | 듌 | 듍 | 듎 | 듏 |
| 0xb4d | 듐 | 듑 | 듒 | 듓 | 듔 | 듕 | 듖 | 듗 | 듘 | 듙 | 듚 | 듛 | 드 | 득 | 듞 | 듟 |
| 0xb4e | 든 | 듡 | 듢 | 듣 | 들 | 듥 | 듦 | 듧 | 듨 | 듩 | 듪 | 듫 | 듬 | 듭 | 듮 | 듯 |
| 0xb4f | 듰 | 등 | 듲 | 듳 | 듴 | 듵 | 듶 | 듷 | 듸 | 듹 | 듺 | 듻 | 듼 | 듽 | 듾 | 듿 |
| 0xb50 | 딀 | 딁 | 딂 | 딃 | 딄 | 딅 | 딆 | 딇 | 딈 | 딉 | 딊 | 딋 | 딌 | 딍 | 딎 | 딏 |
| 0xb51 | 딐 | 딑 | 딒 | 딓 | 디 | 딕 | 딖 | 딗 | 딘 | 딙 | 딚 | 딛 | 딜 | 딝 | 딞 | 딟 |
| 0xb52 | 딠 | 딡 | 딢 | 딣 | 딤 | 딥 | 딦 | 딧 | 딨 | 딩 | 딪 | 딫 | 딬 | 딭 | 딮 | 딯 |
| 0xb53 | 따 | 딱 | 딲 | 딳 | 딴 | 딵 | 딶 | 딷 | 딸 | 딹 | 딺 | 딻 | 딼 | 딽 | 딾 | 딿 |
| 0xb54 | 땀 | 땁 | 땂 | 땃 | 땄 | 땅 | 땆 | 땇 | 땈 | 땉 | 땊 | 땋 | 때 | 땍 | 땎 | 땏 |
| 0xb55 | 땐 | 땑 | 땒 | 땓 | 땔 | 땕 | 땖 | 땗 | 땘 | 땙 | 땚 | 땛 | 땜 | 땝 | 땞 | 땟 |
| 0xb56 | 땠 | 땡 | 땢 | 땣 | 땤 | 땥 | 땦 | 땧 | 땨 | 땩 | 땪 | 땫 | 땬 | 땭 | 땮 | 땯 |
| 0xb57 | 땰 | 땱 | 땲 | 땳 | 땴 | 땵 | 땶 | 땷 | 땸 | 땹 | 땺 | 땻 | 땼 | 땽 | 땾 | 땿 |
| 0xb58 | 떀 | 떁 | 떂 | 떃 | 떄 | 떅 | 떆 | 떇 | 떈 | 떉 | 떊 | 떋 | 떌 | 떍 | 떎 | 떏 |
| 0xb59 | 떐 | 떑 | 떒 | 떓 | 떔 | 떕 | 떖 | 떗 | 떘 | 떙 | 떚 | 떛 | 떜 | 떝 | 떞 | 떟 |
| 0xb5a | 떠 | 떡 | 떢 | 떣 | 떤 | 떥 | 떦 | 떧 | 떨 | 떩 | 떪 | 떫 | 떬 | 떭 | 떮 | 떯 |
| 0xb5b | 떰 | 떱 | 떲 | 떳 | 떴 | 떵 | 떶 | 떷 | 떸 | 떹 | 떺 | 떻 | 떼 | 떽 | 떾 | 떿 |
| 0xb5c | 뗀 | 뗁 | 뗂 | 뗃 | 뗄 | 뗅 | 뗆 | 뗇 | 뗈 | 뗉 | 뗊 | 뗋 | 뗌 | 뗍 | 뗎 | 뗏 |
| 0xb5d | 뗐 | 뗑 | 뗒 | 뗓 | 뗔 | 뗕 | 뗖 | 뗗 | 뗘 | 뗙 | 뗚 | 뗛 | 뗜 | 뗝 | 뗞 | 뗟 |
| 0xb5e | 뗠 | 뗡 | 뗢 | 뗣 | 뗤 | 뗥 | 뗦 | 뗧 | 뗨 | 뗩 | 뗪 | 뗫 | 뗬 | 뗭 | 뗮 | 뗯 |
| 0xb5f | 뗰 | 뗱 | 뗲 | 뗳 | 뗴 | 뗵 | 뗶 | 뗷 | 뗸 | 뗹 | 뗺 | 뗻 | 뗼 | 뗽 | 뗾 | 뗿 |
| 0xb60 | 똀 | 똁 | 똂 | 똃 | 똄 | 똅 | 똆 | 똇 | 똈 | 똉 | 똊 | 똋 | 똌 | 똍 | 똎 | 똏 |
| 0xb61 | 또 | 똑 | 똒 | 똓 | 똔 | 똕 | 똖 | 똗 | 똘 | 똙 | 똚 | 똛 | 똜 | 똝 | 똞 | 똟 |
| 0xb62 | 똠 | 똡 | 똢 | 똣 | 똤 | 똥 | 똦 | 똧 | 똨 | 똩 | 똪 | 똫 | 똬 | 똭 | 똮 | 똯 |
| 0xb63 | 똰 | 똱 | 똲 | 똳 | 똴 | 똵 | 똶 | 똷 | 똸 | 똹 | 똺 | 똻 | 똼 | 똽 | 똾 | 똿 |
| 0xb64 | 뙀 | 뙁 | 뙂 | 뙃 | 뙄 | 뙅 | 뙆 | 뙇 | 뙈 | 뙉 | 뙊 | 뙋 | 뙌 | 뙍 | 뙎 | 뙏 |
| 0xb65 | 뙐 | 뙑 | 뙒 | 뙓 | 뙔 | 뙕 | 뙖 | 뙗 | 뙘 | 뙙 | 뙚 | 뙛 | 뙜 | 뙝 | 뙞 | 뙟 |
| 0xb66 | 뙠 | 뙡 | 뙢 | 뙣 | 뙤 | 뙥 | 뙦 | 뙧 | 뙨 | 뙩 | 뙪 | 뙫 | 뙬 | 뙭 | 뙮 | 뙯 |
| 0xb67 | 뙰 | 뙱 | 뙲 | 뙳 | 뙴 | 뙵 | 뙶 | 뙷 | 뙸 | 뙹 | 뙺 | 뙻 | 뙼 | 뙽 | 뙾 | 뙿 |
| 0xb68 | 뚀 | 뚁 | 뚂 | 뚃 | 뚄 | 뚅 | 뚆 | 뚇 | 뚈 | 뚉 | 뚊 | 뚋 | 뚌 | 뚍 | 뚎 | 뚏 |
| 0xb69 | 뚐 | 뚑 | 뚒 | 뚓 | 뚔 | 뚕 | 뚖 | 뚗 | 뚘 | 뚙 | 뚚 | 뚛 | 뚜 | 뚝 | 뚞 | 뚟 |
| 0xb6a | 뚠 | 뚡 | 뚢 | 뚣 | 뚤 | 뚥 | 뚦 | 뚧 | 뚨 | 뚩 | 뚪 | 뚫 | 뚬 | 뚭 | 뚮 | 뚯 |
| 0xb6b | 뚰 | 뚱 | 뚲 | 뚳 | 뚴 | 뚵 | 뚶 | 뚷 | 뚸 | 뚹 | 뚺 | 뚻 | 뚼 | 뚽 | 뚾 | 뚿 |
| 0xb6c | 뛀 | 뛁 | 뛂 | 뛃 | 뛄 | 뛅 | 뛆 | 뛇 | 뛈 | 뛉 | 뛊 | 뛋 | 뛌 | 뛍 | 뛎 | 뛏 |
| 0xb6d | 뛐 | 뛑 | 뛒 | 뛓 | 뛔 | 뛕 | 뛖 | 뛗 | 뛘 | 뛙 | 뛚 | 뛛 | 뛜 | 뛝 | 뛞 | 뛟 |
| 0xb6e | 뛠 | 뛡 | 뛢 | 뛣 | 뛤 | 뛥 | 뛦 | 뛧 | 뛨 | 뛩 | 뛪 | 뛫 | 뛬 | 뛭 | 뛮 | 뛯 |
| 0xb6f | 뛰 | 뛱 | 뛲 | 뛳 | 뛴 | 뛵 | 뛶 | 뛷 | 뛸 | 뛹 | 뛺 | 뛻 | 뛼 | 뛽 | 뛾 | 뛿 |
| 0xb70 | 뜀 | 뜁 | 뜂 | 뜃 | 뜄 | 뜅 | 뜆 | 뜇 | 뜈 | 뜉 | 뜊 | 뜋 | 뜌 | 뜍 | 뜎 | 뜏 |
| 0xb71 | 뜐 | 뜑 | 뜒 | 뜓 | 뜔 | 뜕 | 뜖 | 뜗 | 뜘 | 뜙 | 뜚 | 뜛 | 뜜 | 뜝 | 뜞 | 뜟 |
| 0xb72 | 뜠 | 뜡 | 뜢 | 뜣 | 뜤 | 뜥 | 뜦 | 뜧 | 뜨 | 뜩 | 뜪 | 뜫 | 뜬 | 뜭 | 뜮 | 뜯 |
| 0xb73 | 뜰 | 뜱 | 뜲 | 뜳 | 뜴 | 뜵 | 뜶 | 뜷 | 뜸 | 뜹 | 뜺 | 뜻 | 뜼 | 뜽 | 뜾 | 뜿 |
| 0xb74 | 띀 | 띁 | 띂 | 띃 | 띄 | 띅 | 띆 | 띇 | 띈 | 띉 | 띊 | 띋 | 띌 | 띍 | 띎 | 띏 |
| 0xb75 | 띐 | 띑 | 띒 | 띓 | 띔 | 띕 | 띖 | 띗 | 띘 | 띙 | 띚 | 띛 | 띜 | 띝 | 띞 | 띟 |
| 0xb76 | 띠 | 띡 | 띢 | 띣 | 띤 | 띥 | 띦 | 띧 | 띨 | 띩 | 띪 | 띫 | 띬 | 띭 | 띮 | 띯 |
| 0xb77 | 띰 | 띱 | 띲 | 띳 | 띴 | 띵 | 띶 | 띷 | 띸 | 띹 | 띺 | 띻 | 라 | 락 | 띾 | 띿 |
| 0xb78 | 란 | 랁 | 랂 | 랃 | 랄 | 랅 | 랆 | 랇 | 랈 | 랉 | 랊 | 랋 | 람 | 랍 | 랎 | 랏 |
| 0xb79 | 랐 | 랑 | 랒 | 랓 | 랔 | 랕 | 랖 | 랗 | 래 | 랙 | 랚 | 랛 | 랜 | 랝 | 랞 | 랟 |
| 0xb7a | 랠 | 랡 | 랢 | 랣 | 랤 | 랥 | 랦 | 랧 | 램 | 랩 | 랪 | 랫 | 랬 | 랭 | 랮 | 랯 |
| 0xb7b | 랰 | 랱 | 랲 | 랳 | 랴 | 략 | 랶 | 랷 | 랸 | 랹 | 랺 | 랻 | 랼 | 랽 | 랾 | 랿 |
| 0xb7c | 럀 | 럁 | 럂 | 럃 | 럄 | 럅 | 럆 | 럇 | 럈 | 량 | 럊 | 럋 | 럌 | 럍 | 럎 | 럏 |
| 0xb7d | 럐 | 럑 | 럒 | 럓 | 럔 | 럕 | 럖 | 럗 | 럘 | 럙 | 럚 | 럛 | 럜 | 럝 | 럞 | 럟 |
| 0xb7e | 럠 | 럡 | 럢 | 럣 | 럤 | 럥 | 럦 | 럧 | 럨 | 럩 | 럪 | 럫 | 러 | 럭 | 럮 | 럯 |
| 0xb7f | 런 | 럱 | 럲 | 럳 | 럴 | 럵 | 럶 | 럷 | 럸 | 럹 | 럺 | 럻 | 럼 | 럽 | 럾 | 럿 |
| 0xb80 | 렀 | 렁 | 렂 | 렃 | 렄 | 렅 | 렆 | 렇 | 레 | 렉 | 렊 | 렋 | 렌 | 렍 | 렎 | 렏 |
| 0xb81 | 렐 | 렑 | 렒 | 렓 | 렔 | 렕 | 렖 | 렗 | 렘 | 렙 | 렚 | 렛 | 렜 | 렝 | 렞 | 렟 |
| 0xb82 | 렠 | 렡 | 렢 | 렣 | 려 | 력 | 렦 | 렧 | 련 | 렩 | 렪 | 렫 | 렬 | 렭 | 렮 | 렯 |
| 0xb83 | 렰 | 렱 | 렲 | 렳 | 렴 | 렵 | 렶 | 렷 | 렸 | 령 | 렺 | 렻 | 렼 | 렽 | 렾 | 렿 |
| 0xb84 | 례 | 롁 | 롂 | 롃 | 롄 | 롅 | 롆 | 롇 | 롈 | 롉 | 롊 | 롋 | 롌 | 롍 | 롎 | 롏 |
| 0xb85 | 롐 | 롑 | 롒 | 롓 | 롔 | 롕 | 롖 | 롗 | 롘 | 롙 | 롚 | 롛 | 로 | 록 | 롞 | 롟 |
| 0xb86 | 론 | 롡 | 롢 | 롣 | 롤 | 롥 | 롦 | 롧 | 롨 | 롩 | 롪 | 롫 | 롬 | 롭 | 롮 | 롯 |
| 0xb87 | 롰 | 롱 | 롲 | 롳 | 롴 | 롵 | 롶 | 롷 | 롸 | 롹 | 롺 | 롻 | 롼 | 롽 | 롾 | 롿 |
| 0xb88 | 뢀 | 뢁 | 뢂 | 뢃 | 뢄 | 뢅 | 뢆 | 뢇 | 뢈 | 뢉 | 뢊 | 뢋 | 뢌 | 뢍 | 뢎 | 뢏 |
| 0xb89 | 뢐 | 뢑 | 뢒 | 뢓 | 뢔 | 뢕 | 뢖 | 뢗 | 뢘 | 뢙 | 뢚 | 뢛 | 뢜 | 뢝 | 뢞 | 뢟 |
| 0xb8a | 뢠 | 뢡 | 뢢 | 뢣 | 뢤 | 뢥 | 뢦 | 뢧 | 뢨 | 뢩 | 뢪 | 뢫 | 뢬 | 뢭 | 뢮 | 뢯 |
| 0xb8b | 뢰 | 뢱 | 뢲 | 뢳 | 뢴 | 뢵 | 뢶 | 뢷 | 뢸 | 뢹 | 뢺 | 뢻 | 뢼 | 뢽 | 뢾 | 뢿 |
| 0xb8c | 룀 | 룁 | 룂 | 룃 | 룄 | 룅 | 룆 | 룇 | 룈 | 룉 | 룊 | 룋 | 료 | 룍 | 룎 | 룏 |
| 0xb8d | 룐 | 룑 | 룒 | 룓 | 룔 | 룕 | 룖 | 룗 | 룘 | 룙 | 룚 | 룛 | 룜 | 룝 | 룞 | 룟 |
| 0xb8e | 룠 | 룡 | 룢 | 룣 | 룤 | 룥 | 룦 | 룧 | 루 | 룩 | 룪 | 룫 | 룬 | 룭 | 룮 | 룯 |
| 0xb8f | 룰 | 룱 | 룲 | 룳 | 룴 | 룵 | 룶 | 룷 | 룸 | 룹 | 룺 | 룻 | 룼 | 룽 | 룾 | 룿 |
| 0xb90 | 뤀 | 뤁 | 뤂 | 뤃 | 뤄 | 뤅 | 뤆 | 뤇 | 뤈 | 뤉 | 뤊 | 뤋 | 뤌 | 뤍 | 뤎 | 뤏 |
| 0xb91 | 뤐 | 뤑 | 뤒 | 뤓 | 뤔 | 뤕 | 뤖 | 뤗 | 뤘 | 뤙 | 뤚 | 뤛 | 뤜 | 뤝 | 뤞 | 뤟 |
| 0xb92 | 뤠 | 뤡 | 뤢 | 뤣 | 뤤 | 뤥 | 뤦 | 뤧 | 뤨 | 뤩 | 뤪 | 뤫 | 뤬 | 뤭 | 뤮 | 뤯 |
| 0xb93 | 뤰 | 뤱 | 뤲 | 뤳 | 뤴 | 뤵 | 뤶 | 뤷 | 뤸 | 뤹 | 뤺 | 뤻 | 뤼 | 뤽 | 뤾 | 뤿 |
| 0xb94 | 륀 | 륁 | 륂 | 륃 | 륄 | 륅 | 륆 | 륇 | 륈 | 륉 | 륊 | 륋 | 륌 | 륍 | 륎 | 륏 |
| 0xb95 | 륐 | 륑 | 륒 | 륓 | 륔 | 륕 | 륖 | 륗 | 류 | 륙 | 륚 | 륛 | 륜 | 륝 | 륞 | 륟 |
| 0xb96 | 률 | 륡 | 륢 | 륣 | 륤 | 륥 | 륦 | 륧 | 륨 | 륩 | 륪 | 륫 | 륬 | 륭 | 륮 | 륯 |
| 0xb97 | 륰 | 륱 | 륲 | 륳 | 르 | 륵 | 륶 | 륷 | 른 | 륹 | 륺 | 륻 | 를 | 륽 | 륾 | 륿 |
| 0xb98 | 릀 | 릁 | 릂 | 릃 | 름 | 릅 | 릆 | 릇 | 릈 | 릉 | 릊 | 릋 | 릌 | 릍 | 릎 | 릏 |
| 0xb99 | 릐 | 릑 | 릒 | 릓 | 릔 | 릕 | 릖 | 릗 | 릘 | 릙 | 릚 | 릛 | 릜 | 릝 | 릞 | 릟 |
| 0xb9a | 릠 | 릡 | 릢 | 릣 | 릤 | 릥 | 릦 | 릧 | 릨 | 릩 | 릪 | 릫 | 리 | 릭 | 릮 | 릯 |
| 0xb9b | 린 | 릱 | 릲 | 릳 | 릴 | 릵 | 릶 | 릷 | 릸 | 릹 | 릺 | 릻 | 림 | 립 | 릾 | 릿 |
| 0xb9c | 맀 | 링 | 맂 | 맃 | 맄 | 맅 | 맆 | 맇 | 마 | 막 | 맊 | 맋 | 만 | 맍 | 많 | 맏 |
| 0xb9d | 말 | 맑 | 맒 | 맓 | 맔 | 맕 | 맖 | 맗 | 맘 | 맙 | 맚 | 맛 | 맜 | 망 | 맞 | 맟 |
| 0xb9e | 맠 | 맡 | 맢 | 맣 | 매 | 맥 | 맦 | 맧 | 맨 | 맩 | 맪 | 맫 | 맬 | 맭 | 맮 | 맯 |
| 0xb9f | 맰 | 맱 | 맲 | 맳 | 맴 | 맵 | 맶 | 맷 | 맸 | 맹 | 맺 | 맻 | 맼 | 맽 | 맾 | 맿 |
| 0xba0 | 먀 | 먁 | 먂 | 먃 | 먄 | 먅 | 먆 | 먇 | 먈 | 먉 | 먊 | 먋 | 먌 | 먍 | 먎 | 먏 |
| 0xba1 | 먐 | 먑 | 먒 | 먓 | 먔 | 먕 | 먖 | 먗 | 먘 | 먙 | 먚 | 먛 | 먜 | 먝 | 먞 | 먟 |
| 0xba2 | 먠 | 먡 | 먢 | 먣 | 먤 | 먥 | 먦 | 먧 | 먨 | 먩 | 먪 | 먫 | 먬 | 먭 | 먮 | 먯 |
| 0xba3 | 먰 | 먱 | 먲 | 먳 | 먴 | 먵 | 먶 | 먷 | 머 | 먹 | 먺 | 먻 | 먼 | 먽 | 먾 | 먿 |
| 0xba4 | 멀 | 멁 | 멂 | 멃 | 멄 | 멅 | 멆 | 멇 | 멈 | 멉 | 멊 | 멋 | 멌 | 멍 | 멎 | 멏 |
| 0xba5 | 멐 | 멑 | 멒 | 멓 | 메 | 멕 | 멖 | 멗 | 멘 | 멙 | 멚 | 멛 | 멜 | 멝 | 멞 | 멟 |
| 0xba6 | 멠 | 멡 | 멢 | 멣 | 멤 | 멥 | 멦 | 멧 | 멨 | 멩 | 멪 | 멫 | 멬 | 멭 | 멮 | 멯 |
| 0xba7 | 며 | 멱 | 멲 | 멳 | 면 | 멵 | 멶 | 멷 | 멸 | 멹 | 멺 | 멻 | 멼 | 멽 | 멾 | 멿 |
| 0xba8 | 몀 | 몁 | 몂 | 몃 | 몄 | 명 | 몆 | 몇 | 몈 | 몉 | 몊 | 몋 | 몌 | 몍 | 몎 | 몏 |
| 0xba9 | 몐 | 몑 | 몒 | 몓 | 몔 | 몕 | 몖 | 몗 | 몘 | 몙 | 몚 | 몛 | 몜 | 몝 | 몞 | 몟 |
| 0xbaa | 몠 | 몡 | 몢 | 몣 | 몤 | 몥 | 몦 | 몧 | 모 | 목 | 몪 | 몫 | 몬 | 몭 | 몮 | 몯 |
| 0xbab | 몰 | 몱 | 몲 | 몳 | 몴 | 몵 | 몶 | 몷 | 몸 | 몹 | 몺 | 못 | 몼 | 몽 | 몾 | 몿 |
| 0xbac | 뫀 | 뫁 | 뫂 | 뫃 | 뫄 | 뫅 | 뫆 | 뫇 | 뫈 | 뫉 | 뫊 | 뫋 | 뫌 | 뫍 | 뫎 | 뫏 |
| 0xbad | 뫐 | 뫑 | 뫒 | 뫓 | 뫔 | 뫕 | 뫖 | 뫗 | 뫘 | 뫙 | 뫚 | 뫛 | 뫜 | 뫝 | 뫞 | 뫟 |
| 0xbae | 뫠 | 뫡 | 뫢 | 뫣 | 뫤 | 뫥 | 뫦 | 뫧 | 뫨 | 뫩 | 뫪 | 뫫 | 뫬 | 뫭 | 뫮 | 뫯 |
| 0xbaf | 뫰 | 뫱 | 뫲 | 뫳 | 뫴 | 뫵 | 뫶 | 뫷 | 뫸 | 뫹 | 뫺 | 뫻 | 뫼 | 뫽 | 뫾 | 뫿 |
| 0xbb0 | 묀 | 묁 | 묂 | 묃 | 묄 | 묅 | 묆 | 묇 | 묈 | 묉 | 묊 | 묋 | 묌 | 묍 | 묎 | 묏 |
| 0xbb1 | 묐 | 묑 | 묒 | 묓 | 묔 | 묕 | 묖 | 묗 | 묘 | 묙 | 묚 | 묛 | 묜 | 묝 | 묞 | 묟 |
| 0xbb2 | 묠 | 묡 | 묢 | 묣 | 묤 | 묥 | 묦 | 묧 | 묨 | 묩 | 묪 | 묫 | 묬 | 묭 | 묮 | 묯 |
| 0xbb3 | 묰 | 묱 | 묲 | 묳 | 무 | 묵 | 묶 | 묷 | 문 | 묹 | 묺 | 묻 | 물 | 묽 | 묾 | 묿 |
| 0xbb4 | 뭀 | 뭁 | 뭂 | 뭃 | 뭄 | 뭅 | 뭆 | 뭇 | 뭈 | 뭉 | 뭊 | 뭋 | 뭌 | 뭍 | 뭎 | 뭏 |
| 0xbb5 | 뭐 | 뭑 | 뭒 | 뭓 | 뭔 | 뭕 | 뭖 | 뭗 | 뭘 | 뭙 | 뭚 | 뭛 | 뭜 | 뭝 | 뭞 | 뭟 |
| 0xbb6 | 뭠 | 뭡 | 뭢 | 뭣 | 뭤 | 뭥 | 뭦 | 뭧 | 뭨 | 뭩 | 뭪 | 뭫 | 뭬 | 뭭 | 뭮 | 뭯 |
| 0xbb7 | 뭰 | 뭱 | 뭲 | 뭳 | 뭴 | 뭵 | 뭶 | 뭷 | 뭸 | 뭹 | 뭺 | 뭻 | 뭼 | 뭽 | 뭾 | 뭿 |
| 0xbb8 | 뮀 | 뮁 | 뮂 | 뮃 | 뮄 | 뮅 | 뮆 | 뮇 | 뮈 | 뮉 | 뮊 | 뮋 | 뮌 | 뮍 | 뮎 | 뮏 |
| 0xbb9 | 뮐 | 뮑 | 뮒 | 뮓 | 뮔 | 뮕 | 뮖 | 뮗 | 뮘 | 뮙 | 뮚 | 뮛 | 뮜 | 뮝 | 뮞 | 뮟 |
| 0xbba | 뮠 | 뮡 | 뮢 | 뮣 | 뮤 | 뮥 | 뮦 | 뮧 | 뮨 | 뮩 | 뮪 | 뮫 | 뮬 | 뮭 | 뮮 | 뮯 |
| 0xbbb | 뮰 | 뮱 | 뮲 | 뮳 | 뮴 | 뮵 | 뮶 | 뮷 | 뮸 | 뮹 | 뮺 | 뮻 | 뮼 | 뮽 | 뮾 | 뮿 |
| 0xbbc | 므 | 믁 | 믂 | 믃 | 믄 | 믅 | 믆 | 믇 | 믈 | 믉 | 믊 | 믋 | 믌 | 믍 | 믎 | 믏 |
| 0xbbd | 믐 | 믑 | 믒 | 믓 | 믔 | 믕 | 믖 | 믗 | 믘 | 믙 | 믚 | 믛 | 믜 | 믝 | 믞 | 믟 |
| 0xbbe | 믠 | 믡 | 믢 | 믣 | 믤 | 믥 | 믦 | 믧 | 믨 | 믩 | 믪 | 믫 | 믬 | 믭 | 믮 | 믯 |
| 0xbbf | 믰 | 믱 | 믲 | 믳 | 믴 | 믵 | 믶 | 믷 | 미 | 믹 | 믺 | 믻 | 민 | 믽 | 믾 | 믿 |
| 0xbc0 | 밀 | 밁 | 밂 | 밃 | 밄 | 밅 | 밆 | 밇 | 밈 | 밉 | 밊 | 밋 | 밌 | 밍 | 밎 | 및 |
| 0xbc1 | 밐 | 밑 | 밒 | 밓 | 바 | 박 | 밖 | 밗 | 반 | 밙 | 밚 | 받 | 발 | 밝 | 밞 | 밟 |
| 0xbc2 | 밠 | 밡 | 밢 | 밣 | 밤 | 밥 | 밦 | 밧 | 밨 | 방 | 밪 | 밫 | 밬 | 밭 | 밮 | 밯 |
| 0xbc3 | 배 | 백 | 밲 | 밳 | 밴 | 밵 | 밶 | 밷 | 밸 | 밹 | 밺 | 밻 | 밼 | 밽 | 밾 | 밿 |
| 0xbc4 | 뱀 | 뱁 | 뱂 | 뱃 | 뱄 | 뱅 | 뱆 | 뱇 | 뱈 | 뱉 | 뱊 | 뱋 | 뱌 | 뱍 | 뱎 | 뱏 |
| 0xbc5 | 뱐 | 뱑 | 뱒 | 뱓 | 뱔 | 뱕 | 뱖 | 뱗 | 뱘 | 뱙 | 뱚 | 뱛 | 뱜 | 뱝 | 뱞 | 뱟 |
| 0xbc6 | 뱠 | 뱡 | 뱢 | 뱣 | 뱤 | 뱥 | 뱦 | 뱧 | 뱨 | 뱩 | 뱪 | 뱫 | 뱬 | 뱭 | 뱮 | 뱯 |
| 0xbc7 | 뱰 | 뱱 | 뱲 | 뱳 | 뱴 | 뱵 | 뱶 | 뱷 | 뱸 | 뱹 | 뱺 | 뱻 | 뱼 | 뱽 | 뱾 | 뱿 |
| 0xbc8 | 벀 | 벁 | 벂 | 벃 | 버 | 벅 | 벆 | 벇 | 번 | 벉 | 벊 | 벋 | 벌 | 벍 | 벎 | 벏 |
| 0xbc9 | 벐 | 벑 | 벒 | 벓 | 범 | 법 | 벖 | 벗 | 벘 | 벙 | 벚 | 벛 | 벜 | 벝 | 벞 | 벟 |
| 0xbca | 베 | 벡 | 벢 | 벣 | 벤 | 벥 | 벦 | 벧 | 벨 | 벩 | 벪 | 벫 | 벬 | 벭 | 벮 | 벯 |
| 0xbcb | 벰 | 벱 | 벲 | 벳 | 벴 | 벵 | 벶 | 벷 | 벸 | 벹 | 벺 | 벻 | 벼 | 벽 | 벾 | 벿 |
| 0xbcc | 변 | 볁 | 볂 | 볃 | 별 | 볅 | 볆 | 볇 | 볈 | 볉 | 볊 | 볋 | 볌 | 볍 | 볎 | 볏 |
| 0xbcd | 볐 | 병 | 볒 | 볓 | 볔 | 볕 | 볖 | 볗 | 볘 | 볙 | 볚 | 볛 | 볜 | 볝 | 볞 | 볟 |
| 0xbce | 볠 | 볡 | 볢 | 볣 | 볤 | 볥 | 볦 | 볧 | 볨 | 볩 | 볪 | 볫 | 볬 | 볭 | 볮 | 볯 |
| 0xbcf | 볰 | 볱 | 볲 | 볳 | 보 | 복 | 볶 | 볷 | 본 | 볹 | 볺 | 볻 | 볼 | 볽 | 볾 | 볿 |
| 0xbd0 | 봀 | 봁 | 봂 | 봃 | 봄 | 봅 | 봆 | 봇 | 봈 | 봉 | 봊 | 봋 | 봌 | 봍 | 봎 | 봏 |
| 0xbd1 | 봐 | 봑 | 봒 | 봓 | 봔 | 봕 | 봖 | 봗 | 봘 | 봙 | 봚 | 봛 | 봜 | 봝 | 봞 | 봟 |
| 0xbd2 | 봠 | 봡 | 봢 | 봣 | 봤 | 봥 | 봦 | 봧 | 봨 | 봩 | 봪 | 봫 | 봬 | 봭 | 봮 | 봯 |
| 0xbd3 | 봰 | 봱 | 봲 | 봳 | 봴 | 봵 | 봶 | 봷 | 봸 | 봹 | 봺 | 봻 | 봼 | 봽 | 봾 | 봿 |
| 0xbd4 | 뵀 | 뵁 | 뵂 | 뵃 | 뵄 | 뵅 | 뵆 | 뵇 | 뵈 | 뵉 | 뵊 | 뵋 | 뵌 | 뵍 | 뵎 | 뵏 |
| 0xbd5 | 뵐 | 뵑 | 뵒 | 뵓 | 뵔 | 뵕 | 뵖 | 뵗 | 뵘 | 뵙 | 뵚 | 뵛 | 뵜 | 뵝 | 뵞 | 뵟 |
| 0xbd6 | 뵠 | 뵡 | 뵢 | 뵣 | 뵤 | 뵥 | 뵦 | 뵧 | 뵨 | 뵩 | 뵪 | 뵫 | 뵬 | 뵭 | 뵮 | 뵯 |
| 0xbd7 | 뵰 | 뵱 | 뵲 | 뵳 | 뵴 | 뵵 | 뵶 | 뵷 | 뵸 | 뵹 | 뵺 | 뵻 | 뵼 | 뵽 | 뵾 | 뵿 |
| 0xbd8 | 부 | 북 | 붂 | 붃 | 분 | 붅 | 붆 | 붇 | 불 | 붉 | 붊 | 붋 | 붌 | 붍 | 붎 | 붏 |
| 0xbd9 | 붐 | 붑 | 붒 | 붓 | 붔 | 붕 | 붖 | 붗 | 붘 | 붙 | 붚 | 붛 | 붜 | 붝 | 붞 | 붟 |
| 0xbda | 붠 | 붡 | 붢 | 붣 | 붤 | 붥 | 붦 | 붧 | 붨 | 붩 | 붪 | 붫 | 붬 | 붭 | 붮 | 붯 |
| 0xbdb | 붰 | 붱 | 붲 | 붳 | 붴 | 붵 | 붶 | 붷 | 붸 | 붹 | 붺 | 붻 | 붼 | 붽 | 붾 | 붿 |
| 0xbdc | 뷀 | 뷁 | 뷂 | 뷃 | 뷄 | 뷅 | 뷆 | 뷇 | 뷈 | 뷉 | 뷊 | 뷋 | 뷌 | 뷍 | 뷎 | 뷏 |
| 0xbdd | 뷐 | 뷑 | 뷒 | 뷓 | 뷔 | 뷕 | 뷖 | 뷗 | 뷘 | 뷙 | 뷚 | 뷛 | 뷜 | 뷝 | 뷞 | 뷟 |
| 0xbde | 뷠 | 뷡 | 뷢 | 뷣 | 뷤 | 뷥 | 뷦 | 뷧 | 뷨 | 뷩 | 뷪 | 뷫 | 뷬 | 뷭 | 뷮 | 뷯 |
| 0xbdf | 뷰 | 뷱 | 뷲 | 뷳 | 뷴 | 뷵 | 뷶 | 뷷 | 뷸 | 뷹 | 뷺 | 뷻 | 뷼 | 뷽 | 뷾 | 뷿 |
| 0xbe0 | 븀 | 븁 | 븂 | 븃 | 븄 | 븅 | 븆 | 븇 | 븈 | 븉 | 븊 | 븋 | 브 | 븍 | 븎 | 븏 |
| 0xbe1 | 븐 | 븑 | 븒 | 븓 | 블 | 븕 | 븖 | 븗 | 븘 | 븙 | 븚 | 븛 | 븜 | 븝 | 븞 | 븟 |
| 0xbe2 | 븠 | 븡 | 븢 | 븣 | 븤 | 븥 | 븦 | 븧 | 븨 | 븩 | 븪 | 븫 | 븬 | 븭 | 븮 | 븯 |
| 0xbe3 | 븰 | 븱 | 븲 | 븳 | 븴 | 븵 | 븶 | 븷 | 븸 | 븹 | 븺 | 븻 | 븼 | 븽 | 븾 | 븿 |
| 0xbe4 | 빀 | 빁 | 빂 | 빃 | 비 | 빅 | 빆 | 빇 | 빈 | 빉 | 빊 | 빋 | 빌 | 빍 | 빎 | 빏 |
| 0xbe5 | 빐 | 빑 | 빒 | 빓 | 빔 | 빕 | 빖 | 빗 | 빘 | 빙 | 빚 | 빛 | 빜 | 빝 | 빞 | 빟 |
| 0xbe6 | 빠 | 빡 | 빢 | 빣 | 빤 | 빥 | 빦 | 빧 | 빨 | 빩 | 빪 | 빫 | 빬 | 빭 | 빮 | 빯 |
| 0xbe7 | 빰 | 빱 | 빲 | 빳 | 빴 | 빵 | 빶 | 빷 | 빸 | 빹 | 빺 | 빻 | 빼 | 빽 | 빾 | 빿 |
| 0xbe8 | 뺀 | 뺁 | 뺂 | 뺃 | 뺄 | 뺅 | 뺆 | 뺇 | 뺈 | 뺉 | 뺊 | 뺋 | 뺌 | 뺍 | 뺎 | 뺏 |
| 0xbe9 | 뺐 | 뺑 | 뺒 | 뺓 | 뺔 | 뺕 | 뺖 | 뺗 | 뺘 | 뺙 | 뺚 | 뺛 | 뺜 | 뺝 | 뺞 | 뺟 |
| 0xbea | 뺠 | 뺡 | 뺢 | 뺣 | 뺤 | 뺥 | 뺦 | 뺧 | 뺨 | 뺩 | 뺪 | 뺫 | 뺬 | 뺭 | 뺮 | 뺯 |
| 0xbeb | 뺰 | 뺱 | 뺲 | 뺳 | 뺴 | 뺵 | 뺶 | 뺷 | 뺸 | 뺹 | 뺺 | 뺻 | 뺼 | 뺽 | 뺾 | 뺿 |
| 0xbec | 뻀 | 뻁 | 뻂 | 뻃 | 뻄 | 뻅 | 뻆 | 뻇 | 뻈 | 뻉 | 뻊 | 뻋 | 뻌 | 뻍 | 뻎 | 뻏 |
| 0xbed | 뻐 | 뻑 | 뻒 | 뻓 | 뻔 | 뻕 | 뻖 | 뻗 | 뻘 | 뻙 | 뻚 | 뻛 | 뻜 | 뻝 | 뻞 | 뻟 |
| 0xbee | 뻠 | 뻡 | 뻢 | 뻣 | 뻤 | 뻥 | 뻦 | 뻧 | 뻨 | 뻩 | 뻪 | 뻫 | 뻬 | 뻭 | 뻮 | 뻯 |
| 0xbef | 뻰 | 뻱 | 뻲 | 뻳 | 뻴 | 뻵 | 뻶 | 뻷 | 뻸 | 뻹 | 뻺 | 뻻 | 뻼 | 뻽 | 뻾 | 뻿 |
| 0xbf0 | 뼀 | 뼁 | 뼂 | 뼃 | 뼄 | 뼅 | 뼆 | 뼇 | 뼈 | 뼉 | 뼊 | 뼋 | 뼌 | 뼍 | 뼎 | 뼏 |
| 0xbf1 | 뼐 | 뼑 | 뼒 | 뼓 | 뼔 | 뼕 | 뼖 | 뼗 | 뼘 | 뼙 | 뼚 | 뼛 | 뼜 | 뼝 | 뼞 | 뼟 |
| 0xbf2 | 뼠 | 뼡 | 뼢 | 뼣 | 뼤 | 뼥 | 뼦 | 뼧 | 뼨 | 뼩 | 뼪 | 뼫 | 뼬 | 뼭 | 뼮 | 뼯 |
| 0xbf3 | 뼰 | 뼱 | 뼲 | 뼳 | 뼴 | 뼵 | 뼶 | 뼷 | 뼸 | 뼹 | 뼺 | 뼻 | 뼼 | 뼽 | 뼾 | 뼿 |
| 0xbf4 | 뽀 | 뽁 | 뽂 | 뽃 | 뽄 | 뽅 | 뽆 | 뽇 | 뽈 | 뽉 | 뽊 | 뽋 | 뽌 | 뽍 | 뽎 | 뽏 |
| 0xbf5 | 뽐 | 뽑 | 뽒 | 뽓 | 뽔 | 뽕 | 뽖 | 뽗 | 뽘 | 뽙 | 뽚 | 뽛 | 뽜 | 뽝 | 뽞 | 뽟 |
| 0xbf6 | 뽠 | 뽡 | 뽢 | 뽣 | 뽤 | 뽥 | 뽦 | 뽧 | 뽨 | 뽩 | 뽪 | 뽫 | 뽬 | 뽭 | 뽮 | 뽯 |
| 0xbf7 | 뽰 | 뽱 | 뽲 | 뽳 | 뽴 | 뽵 | 뽶 | 뽷 | 뽸 | 뽹 | 뽺 | 뽻 | 뽼 | 뽽 | 뽾 | 뽿 |
| 0xbf8 | 뾀 | 뾁 | 뾂 | 뾃 | 뾄 | 뾅 | 뾆 | 뾇 | 뾈 | 뾉 | 뾊 | 뾋 | 뾌 | 뾍 | 뾎 | 뾏 |
| 0xbf9 | 뾐 | 뾑 | 뾒 | 뾓 | 뾔 | 뾕 | 뾖 | 뾗 | 뾘 | 뾙 | 뾚 | 뾛 | 뾜 | 뾝 | 뾞 | 뾟 |
| 0xbfa | 뾠 | 뾡 | 뾢 | 뾣 | 뾤 | 뾥 | 뾦 | 뾧 | 뾨 | 뾩 | 뾪 | 뾫 | 뾬 | 뾭 | 뾮 | 뾯 |
| 0xbfb | 뾰 | 뾱 | 뾲 | 뾳 | 뾴 | 뾵 | 뾶 | 뾷 | 뾸 | 뾹 | 뾺 | 뾻 | 뾼 | 뾽 | 뾾 | 뾿 |
| 0xbfc | 뿀 | 뿁 | 뿂 | 뿃 | 뿄 | 뿅 | 뿆 | 뿇 | 뿈 | 뿉 | 뿊 | 뿋 | 뿌 | 뿍 | 뿎 | 뿏 |
| 0xbfd | 뿐 | 뿑 | 뿒 | 뿓 | 뿔 | 뿕 | 뿖 | 뿗 | 뿘 | 뿙 | 뿚 | 뿛 | 뿜 | 뿝 | 뿞 | 뿟 |
| 0xbfe | 뿠 | 뿡 | 뿢 | 뿣 | 뿤 | 뿥 | 뿦 | 뿧 | 뿨 | 뿩 | 뿪 | 뿫 | 뿬 | 뿭 | 뿮 | 뿯 |
| 0xbff | 뿰 | 뿱 | 뿲 | 뿳 | 뿴 | 뿵 | 뿶 | 뿷 | 뿸 | 뿹 | 뿺 | 뿻 | 뿼 | 뿽 | 뿾 | 뿿 |
| 0xc00 | 쀀 | 쀁 | 쀂 | 쀃 | 쀄 | 쀅 | 쀆 | 쀇 | 쀈 | 쀉 | 쀊 | 쀋 | 쀌 | 쀍 | 쀎 | 쀏 |
| 0xc01 | 쀐 | 쀑 | 쀒 | 쀓 | 쀔 | 쀕 | 쀖 | 쀗 | 쀘 | 쀙 | 쀚 | 쀛 | 쀜 | 쀝 | 쀞 | 쀟 |
| 0xc02 | 쀠 | 쀡 | 쀢 | 쀣 | 쀤 | 쀥 | 쀦 | 쀧 | 쀨 | 쀩 | 쀪 | 쀫 | 쀬 | 쀭 | 쀮 | 쀯 |
| 0xc03 | 쀰 | 쀱 | 쀲 | 쀳 | 쀴 | 쀵 | 쀶 | 쀷 | 쀸 | 쀹 | 쀺 | 쀻 | 쀼 | 쀽 | 쀾 | 쀿 |
| 0xc04 | 쁀 | 쁁 | 쁂 | 쁃 | 쁄 | 쁅 | 쁆 | 쁇 | 쁈 | 쁉 | 쁊 | 쁋 | 쁌 | 쁍 | 쁎 | 쁏 |
| 0xc05 | 쁐 | 쁑 | 쁒 | 쁓 | 쁔 | 쁕 | 쁖 | 쁗 | 쁘 | 쁙 | 쁚 | 쁛 | 쁜 | 쁝 | 쁞 | 쁟 |
| 0xc06 | 쁠 | 쁡 | 쁢 | 쁣 | 쁤 | 쁥 | 쁦 | 쁧 | 쁨 | 쁩 | 쁪 | 쁫 | 쁬 | 쁭 | 쁮 | 쁯 |
| 0xc07 | 쁰 | 쁱 | 쁲 | 쁳 | 쁴 | 쁵 | 쁶 | 쁷 | 쁸 | 쁹 | 쁺 | 쁻 | 쁼 | 쁽 | 쁾 | 쁿 |
| 0xc08 | 삀 | 삁 | 삂 | 삃 | 삄 | 삅 | 삆 | 삇 | 삈 | 삉 | 삊 | 삋 | 삌 | 삍 | 삎 | 삏 |
| 0xc09 | 삐 | 삑 | 삒 | 삓 | 삔 | 삕 | 삖 | 삗 | 삘 | 삙 | 삚 | 삛 | 삜 | 삝 | 삞 | 삟 |
| 0xc0a | 삠 | 삡 | 삢 | 삣 | 삤 | 삥 | 삦 | 삧 | 삨 | 삩 | 삪 | 삫 | 사 | 삭 | 삮 | 삯 |
| 0xc0b | 산 | 삱 | 삲 | 삳 | 살 | 삵 | 삶 | 삷 | 삸 | 삹 | 삺 | 삻 | 삼 | 삽 | 삾 | 삿 |
| 0xc0c | 샀 | 상 | 샂 | 샃 | 샄 | 샅 | 샆 | 샇 | 새 | 색 | 샊 | 샋 | 샌 | 샍 | 샎 | 샏 |
| 0xc0d | 샐 | 샑 | 샒 | 샓 | 샔 | 샕 | 샖 | 샗 | 샘 | 샙 | 샚 | 샛 | 샜 | 생 | 샞 | 샟 |
| 0xc0e | 샠 | 샡 | 샢 | 샣 | 샤 | 샥 | 샦 | 샧 | 샨 | 샩 | 샪 | 샫 | 샬 | 샭 | 샮 | 샯 |
| 0xc0f | 샰 | 샱 | 샲 | 샳 | 샴 | 샵 | 샶 | 샷 | 샸 | 샹 | 샺 | 샻 | 샼 | 샽 | 샾 | 샿 |
| 0xc10 | 섀 | 섁 | 섂 | 섃 | 섄 | 섅 | 섆 | 섇 | 섈 | 섉 | 섊 | 섋 | 섌 | 섍 | 섎 | 섏 |
| 0xc11 | 섐 | 섑 | 섒 | 섓 | 섔 | 섕 | 섖 | 섗 | 섘 | 섙 | 섚 | 섛 | 서 | 석 | 섞 | 섟 |
| 0xc12 | 선 | 섡 | 섢 | 섣 | 설 | 섥 | 섦 | 섧 | 섨 | 섩 | 섪 | 섫 | 섬 | 섭 | 섮 | 섯 |
| 0xc13 | 섰 | 성 | 섲 | 섳 | 섴 | 섵 | 섶 | 섷 | 세 | 섹 | 섺 | 섻 | 센 | 섽 | 섾 | 섿 |
| 0xc14 | 셀 | 셁 | 셂 | 셃 | 셄 | 셅 | 셆 | 셇 | 셈 | 셉 | 셊 | 셋 | 셌 | 셍 | 셎 | 셏 |
| 0xc15 | 셐 | 셑 | 셒 | 셓 | 셔 | 셕 | 셖 | 셗 | 션 | 셙 | 셚 | 셛 | 셜 | 셝 | 셞 | 셟 |
| 0xc16 | 셠 | 셡 | 셢 | 셣 | 셤 | 셥 | 셦 | 셧 | 셨 | 셩 | 셪 | 셫 | 셬 | 셭 | 셮 | 셯 |
| 0xc17 | 셰 | 셱 | 셲 | 셳 | 셴 | 셵 | 셶 | 셷 | 셸 | 셹 | 셺 | 셻 | 셼 | 셽 | 셾 | 셿 |
| 0xc18 | 솀 | 솁 | 솂 | 솃 | 솄 | 솅 | 솆 | 솇 | 솈 | 솉 | 솊 | 솋 | 소 | 속 | 솎 | 솏 |
| 0xc19 | 손 | 솑 | 솒 | 솓 | 솔 | 솕 | 솖 | 솗 | 솘 | 솙 | 솚 | 솛 | 솜 | 솝 | 솞 | 솟 |
| 0xc1a | 솠 | 송 | 솢 | 솣 | 솤 | 솥 | 솦 | 솧 | 솨 | 솩 | 솪 | 솫 | 솬 | 솭 | 솮 | 솯 |
| 0xc1b | 솰 | 솱 | 솲 | 솳 | 솴 | 솵 | 솶 | 솷 | 솸 | 솹 | 솺 | 솻 | 솼 | 솽 | 솾 | 솿 |
| 0xc1c | 쇀 | 쇁 | 쇂 | 쇃 | 쇄 | 쇅 | 쇆 | 쇇 | 쇈 | 쇉 | 쇊 | 쇋 | 쇌 | 쇍 | 쇎 | 쇏 |
| 0xc1d | 쇐 | 쇑 | 쇒 | 쇓 | 쇔 | 쇕 | 쇖 | 쇗 | 쇘 | 쇙 | 쇚 | 쇛 | 쇜 | 쇝 | 쇞 | 쇟 |
| 0xc1e | 쇠 | 쇡 | 쇢 | 쇣 | 쇤 | 쇥 | 쇦 | 쇧 | 쇨 | 쇩 | 쇪 | 쇫 | 쇬 | 쇭 | 쇮 | 쇯 |
| 0xc1f | 쇰 | 쇱 | 쇲 | 쇳 | 쇴 | 쇵 | 쇶 | 쇷 | 쇸 | 쇹 | 쇺 | 쇻 | 쇼 | 쇽 | 쇾 | 쇿 |
| 0xc20 | 숀 | 숁 | 숂 | 숃 | 숄 | 숅 | 숆 | 숇 | 숈 | 숉 | 숊 | 숋 | 숌 | 숍 | 숎 | 숏 |
| 0xc21 | 숐 | 숑 | 숒 | 숓 | 숔 | 숕 | 숖 | 숗 | 수 | 숙 | 숚 | 숛 | 순 | 숝 | 숞 | 숟 |
| 0xc22 | 술 | 숡 | 숢 | 숣 | 숤 | 숥 | 숦 | 숧 | 숨 | 숩 | 숪 | 숫 | 숬 | 숭 | 숮 | 숯 |
| 0xc23 | 숰 | 숱 | 숲 | 숳 | 숴 | 숵 | 숶 | 숷 | 숸 | 숹 | 숺 | 숻 | 숼 | 숽 | 숾 | 숿 |
| 0xc24 | 쉀 | 쉁 | 쉂 | 쉃 | 쉄 | 쉅 | 쉆 | 쉇 | 쉈 | 쉉 | 쉊 | 쉋 | 쉌 | 쉍 | 쉎 | 쉏 |
| 0xc25 | 쉐 | 쉑 | 쉒 | 쉓 | 쉔 | 쉕 | 쉖 | 쉗 | 쉘 | 쉙 | 쉚 | 쉛 | 쉜 | 쉝 | 쉞 | 쉟 |
| 0xc26 | 쉠 | 쉡 | 쉢 | 쉣 | 쉤 | 쉥 | 쉦 | 쉧 | 쉨 | 쉩 | 쉪 | 쉫 | 쉬 | 쉭 | 쉮 | 쉯 |
| 0xc27 | 쉰 | 쉱 | 쉲 | 쉳 | 쉴 | 쉵 | 쉶 | 쉷 | 쉸 | 쉹 | 쉺 | 쉻 | 쉼 | 쉽 | 쉾 | 쉿 |
| 0xc28 | 슀 | 슁 | 슂 | 슃 | 슄 | 슅 | 슆 | 슇 | 슈 | 슉 | 슊 | 슋 | 슌 | 슍 | 슎 | 슏 |
| 0xc29 | 슐 | 슑 | 슒 | 슓 | 슔 | 슕 | 슖 | 슗 | 슘 | 슙 | 슚 | 슛 | 슜 | 슝 | 슞 | 슟 |
| 0xc2a | 슠 | 슡 | 슢 | 슣 | 스 | 슥 | 슦 | 슧 | 슨 | 슩 | 슪 | 슫 | 슬 | 슭 | 슮 | 슯 |
| 0xc2b | 슰 | 슱 | 슲 | 슳 | 슴 | 습 | 슶 | 슷 | 슸 | 승 | 슺 | 슻 | 슼 | 슽 | 슾 | 슿 |
| 0xc2c | 싀 | 싁 | 싂 | 싃 | 싄 | 싅 | 싆 | 싇 | 싈 | 싉 | 싊 | 싋 | 싌 | 싍 | 싎 | 싏 |
| 0xc2d | 싐 | 싑 | 싒 | 싓 | 싔 | 싕 | 싖 | 싗 | 싘 | 싙 | 싚 | 싛 | 시 | 식 | 싞 | 싟 |
| 0xc2e | 신 | 싡 | 싢 | 싣 | 실 | 싥 | 싦 | 싧 | 싨 | 싩 | 싪 | 싫 | 심 | 십 | 싮 | 싯 |
| 0xc2f | 싰 | 싱 | 싲 | 싳 | 싴 | 싵 | 싶 | 싷 | 싸 | 싹 | 싺 | 싻 | 싼 | 싽 | 싾 | 싿 |
| 0xc30 | 쌀 | 쌁 | 쌂 | 쌃 | 쌄 | 쌅 | 쌆 | 쌇 | 쌈 | 쌉 | 쌊 | 쌋 | 쌌 | 쌍 | 쌎 | 쌏 |
| 0xc31 | 쌐 | 쌑 | 쌒 | 쌓 | 쌔 | 쌕 | 쌖 | 쌗 | 쌘 | 쌙 | 쌚 | 쌛 | 쌜 | 쌝 | 쌞 | 쌟 |
| 0xc32 | 쌠 | 쌡 | 쌢 | 쌣 | 쌤 | 쌥 | 쌦 | 쌧 | 쌨 | 쌩 | 쌪 | 쌫 | 쌬 | 쌭 | 쌮 | 쌯 |
| 0xc33 | 쌰 | 쌱 | 쌲 | 쌳 | 쌴 | 쌵 | 쌶 | 쌷 | 쌸 | 쌹 | 쌺 | 쌻 | 쌼 | 쌽 | 쌾 | 쌿 |
| 0xc34 | 썀 | 썁 | 썂 | 썃 | 썄 | 썅 | 썆 | 썇 | 썈 | 썉 | 썊 | 썋 | 썌 | 썍 | 썎 | 썏 |
| 0xc35 | 썐 | 썑 | 썒 | 썓 | 썔 | 썕 | 썖 | 썗 | 썘 | 썙 | 썚 | 썛 | 썜 | 썝 | 썞 | 썟 |
| 0xc36 | 썠 | 썡 | 썢 | 썣 | 썤 | 썥 | 썦 | 썧 | 써 | 썩 | 썪 | 썫 | 썬 | 썭 | 썮 | 썯 |
| 0xc37 | 썰 | 썱 | 썲 | 썳 | 썴 | 썵 | 썶 | 썷 | 썸 | 썹 | 썺 | 썻 | 썼 | 썽 | 썾 | 썿 |
| 0xc38 | 쎀 | 쎁 | 쎂 | 쎃 | 쎄 | 쎅 | 쎆 | 쎇 | 쎈 | 쎉 | 쎊 | 쎋 | 쎌 | 쎍 | 쎎 | 쎏 |
| 0xc39 | 쎐 | 쎑 | 쎒 | 쎓 | 쎔 | 쎕 | 쎖 | 쎗 | 쎘 | 쎙 | 쎚 | 쎛 | 쎜 | 쎝 | 쎞 | 쎟 |
| 0xc3a | 쎠 | 쎡 | 쎢 | 쎣 | 쎤 | 쎥 | 쎦 | 쎧 | 쎨 | 쎩 | 쎪 | 쎫 | 쎬 | 쎭 | 쎮 | 쎯 |
| 0xc3b | 쎰 | 쎱 | 쎲 | 쎳 | 쎴 | 쎵 | 쎶 | 쎷 | 쎸 | 쎹 | 쎺 | 쎻 | 쎼 | 쎽 | 쎾 | 쎿 |
| 0xc3c | 쏀 | 쏁 | 쏂 | 쏃 | 쏄 | 쏅 | 쏆 | 쏇 | 쏈 | 쏉 | 쏊 | 쏋 | 쏌 | 쏍 | 쏎 | 쏏 |
| 0xc3d | 쏐 | 쏑 | 쏒 | 쏓 | 쏔 | 쏕 | 쏖 | 쏗 | 쏘 | 쏙 | 쏚 | 쏛 | 쏜 | 쏝 | 쏞 | 쏟 |
| 0xc3e | 쏠 | 쏡 | 쏢 | 쏣 | 쏤 | 쏥 | 쏦 | 쏧 | 쏨 | 쏩 | 쏪 | 쏫 | 쏬 | 쏭 | 쏮 | 쏯 |
| 0xc3f | 쏰 | 쏱 | 쏲 | 쏳 | 쏴 | 쏵 | 쏶 | 쏷 | 쏸 | 쏹 | 쏺 | 쏻 | 쏼 | 쏽 | 쏾 | 쏿 |
| 0xc40 | 쐀 | 쐁 | 쐂 | 쐃 | 쐄 | 쐅 | 쐆 | 쐇 | 쐈 | 쐉 | 쐊 | 쐋 | 쐌 | 쐍 | 쐎 | 쐏 |
| 0xc41 | 쐐 | 쐑 | 쐒 | 쐓 | 쐔 | 쐕 | 쐖 | 쐗 | 쐘 | 쐙 | 쐚 | 쐛 | 쐜 | 쐝 | 쐞 | 쐟 |
| 0xc42 | 쐠 | 쐡 | 쐢 | 쐣 | 쐤 | 쐥 | 쐦 | 쐧 | 쐨 | 쐩 | 쐪 | 쐫 | 쐬 | 쐭 | 쐮 | 쐯 |
| 0xc43 | 쐰 | 쐱 | 쐲 | 쐳 | 쐴 | 쐵 | 쐶 | 쐷 | 쐸 | 쐹 | 쐺 | 쐻 | 쐼 | 쐽 | 쐾 | 쐿 |
| 0xc44 | 쑀 | 쑁 | 쑂 | 쑃 | 쑄 | 쑅 | 쑆 | 쑇 | 쑈 | 쑉 | 쑊 | 쑋 | 쑌 | 쑍 | 쑎 | 쑏 |
| 0xc45 | 쑐 | 쑑 | 쑒 | 쑓 | 쑔 | 쑕 | 쑖 | 쑗 | 쑘 | 쑙 | 쑚 | 쑛 | 쑜 | 쑝 | 쑞 | 쑟 |
| 0xc46 | 쑠 | 쑡 | 쑢 | 쑣 | 쑤 | 쑥 | 쑦 | 쑧 | 쑨 | 쑩 | 쑪 | 쑫 | 쑬 | 쑭 | 쑮 | 쑯 |
| 0xc47 | 쑰 | 쑱 | 쑲 | 쑳 | 쑴 | 쑵 | 쑶 | 쑷 | 쑸 | 쑹 | 쑺 | 쑻 | 쑼 | 쑽 | 쑾 | 쑿 |
| 0xc48 | 쒀 | 쒁 | 쒂 | 쒃 | 쒄 | 쒅 | 쒆 | 쒇 | 쒈 | 쒉 | 쒊 | 쒋 | 쒌 | 쒍 | 쒎 | 쒏 |
| 0xc49 | 쒐 | 쒑 | 쒒 | 쒓 | 쒔 | 쒕 | 쒖 | 쒗 | 쒘 | 쒙 | 쒚 | 쒛 | 쒜 | 쒝 | 쒞 | 쒟 |
| 0xc4a | 쒠 | 쒡 | 쒢 | 쒣 | 쒤 | 쒥 | 쒦 | 쒧 | 쒨 | 쒩 | 쒪 | 쒫 | 쒬 | 쒭 | 쒮 | 쒯 |
| 0xc4b | 쒰 | 쒱 | 쒲 | 쒳 | 쒴 | 쒵 | 쒶 | 쒷 | 쒸 | 쒹 | 쒺 | 쒻 | 쒼 | 쒽 | 쒾 | 쒿 |
| 0xc4c | 쓀 | 쓁 | 쓂 | 쓃 | 쓄 | 쓅 | 쓆 | 쓇 | 쓈 | 쓉 | 쓊 | 쓋 | 쓌 | 쓍 | 쓎 | 쓏 |
| 0xc4d | 쓐 | 쓑 | 쓒 | 쓓 | 쓔 | 쓕 | 쓖 | 쓗 | 쓘 | 쓙 | 쓚 | 쓛 | 쓜 | 쓝 | 쓞 | 쓟 |
| 0xc4e | 쓠 | 쓡 | 쓢 | 쓣 | 쓤 | 쓥 | 쓦 | 쓧 | 쓨 | 쓩 | 쓪 | 쓫 | 쓬 | 쓭 | 쓮 | 쓯 |
| 0xc4f | 쓰 | 쓱 | 쓲 | 쓳 | 쓴 | 쓵 | 쓶 | 쓷 | 쓸 | 쓹 | 쓺 | 쓻 | 쓼 | 쓽 | 쓾 | 쓿 |
| 0xc50 | 씀 | 씁 | 씂 | 씃 | 씄 | 씅 | 씆 | 씇 | 씈 | 씉 | 씊 | 씋 | 씌 | 씍 | 씎 | 씏 |
| 0xc51 | 씐 | 씑 | 씒 | 씓 | 씔 | 씕 | 씖 | 씗 | 씘 | 씙 | 씚 | 씛 | 씜 | 씝 | 씞 | 씟 |
| 0xc52 | 씠 | 씡 | 씢 | 씣 | 씤 | 씥 | 씦 | 씧 | 씨 | 씩 | 씪 | 씫 | 씬 | 씭 | 씮 | 씯 |
| 0xc53 | 씰 | 씱 | 씲 | 씳 | 씴 | 씵 | 씶 | 씷 | 씸 | 씹 | 씺 | 씻 | 씼 | 씽 | 씾 | 씿 |
| 0xc54 | 앀 | 앁 | 앂 | 앃 | 아 | 악 | 앆 | 앇 | 안 | 앉 | 않 | 앋 | 알 | 앍 | 앎 | 앏 |
| 0xc55 | 앐 | 앑 | 앒 | 앓 | 암 | 압 | 앖 | 앗 | 았 | 앙 | 앚 | 앛 | 앜 | 앝 | 앞 | 앟 |
| 0xc56 | 애 | 액 | 앢 | 앣 | 앤 | 앥 | 앦 | 앧 | 앨 | 앩 | 앪 | 앫 | 앬 | 앭 | 앮 | 앯 |
| 0xc57 | 앰 | 앱 | 앲 | 앳 | 앴 | 앵 | 앶 | 앷 | 앸 | 앹 | 앺 | 앻 | 야 | 약 | 앾 | 앿 |
| 0xc58 | 얀 | 얁 | 얂 | 얃 | 얄 | 얅 | 얆 | 얇 | 얈 | 얉 | 얊 | 얋 | 얌 | 얍 | 얎 | 얏 |
| 0xc59 | 얐 | 양 | 얒 | 얓 | 얔 | 얕 | 얖 | 얗 | 얘 | 얙 | 얚 | 얛 | 얜 | 얝 | 얞 | 얟 |
| 0xc5a | 얠 | 얡 | 얢 | 얣 | 얤 | 얥 | 얦 | 얧 | 얨 | 얩 | 얪 | 얫 | 얬 | 얭 | 얮 | 얯 |
| 0xc5b | 얰 | 얱 | 얲 | 얳 | 어 | 억 | 얶 | 얷 | 언 | 얹 | 얺 | 얻 | 얼 | 얽 | 얾 | 얿 |
| 0xc5c | 엀 | 엁 | 엂 | 엃 | 엄 | 업 | 없 | 엇 | 었 | 엉 | 엊 | 엋 | 엌 | 엍 | 엎 | 엏 |
| 0xc5d | 에 | 엑 | 엒 | 엓 | 엔 | 엕 | 엖 | 엗 | 엘 | 엙 | 엚 | 엛 | 엜 | 엝 | 엞 | 엟 |
| 0xc5e | 엠 | 엡 | 엢 | 엣 | 엤 | 엥 | 엦 | 엧 | 엨 | 엩 | 엪 | 엫 | 여 | 역 | 엮 | 엯 |
| 0xc5f | 연 | 엱 | 엲 | 엳 | 열 | 엵 | 엶 | 엷 | 엸 | 엹 | 엺 | 엻 | 염 | 엽 | 엾 | 엿 |
| 0xc60 | 였 | 영 | 옂 | 옃 | 옄 | 옅 | 옆 | 옇 | 예 | 옉 | 옊 | 옋 | 옌 | 옍 | 옎 | 옏 |
| 0xc61 | 옐 | 옑 | 옒 | 옓 | 옔 | 옕 | 옖 | 옗 | 옘 | 옙 | 옚 | 옛 | 옜 | 옝 | 옞 | 옟 |
| 0xc62 | 옠 | 옡 | 옢 | 옣 | 오 | 옥 | 옦 | 옧 | 온 | 옩 | 옪 | 옫 | 올 | 옭 | 옮 | 옯 |
| 0xc63 | 옰 | 옱 | 옲 | 옳 | 옴 | 옵 | 옶 | 옷 | 옸 | 옹 | 옺 | 옻 | 옼 | 옽 | 옾 | 옿 |
| 0xc64 | 와 | 왁 | 왂 | 왃 | 완 | 왅 | 왆 | 왇 | 왈 | 왉 | 왊 | 왋 | 왌 | 왍 | 왎 | 왏 |
| 0xc65 | 왐 | 왑 | 왒 | 왓 | 왔 | 왕 | 왖 | 왗 | 왘 | 왙 | 왚 | 왛 | 왜 | 왝 | 왞 | 왟 |
| 0xc66 | 왠 | 왡 | 왢 | 왣 | 왤 | 왥 | 왦 | 왧 | 왨 | 왩 | 왪 | 왫 | 왬 | 왭 | 왮 | 왯 |
| 0xc67 | 왰 | 왱 | 왲 | 왳 | 왴 | 왵 | 왶 | 왷 | 외 | 왹 | 왺 | 왻 | 왼 | 왽 | 왾 | 왿 |
| 0xc68 | 욀 | 욁 | 욂 | 욃 | 욄 | 욅 | 욆 | 욇 | 욈 | 욉 | 욊 | 욋 | 욌 | 욍 | 욎 | 욏 |
| 0xc69 | 욐 | 욑 | 욒 | 욓 | 요 | 욕 | 욖 | 욗 | 욘 | 욙 | 욚 | 욛 | 욜 | 욝 | 욞 | 욟 |
| 0xc6a | 욠 | 욡 | 욢 | 욣 | 욤 | 욥 | 욦 | 욧 | 욨 | 용 | 욪 | 욫 | 욬 | 욭 | 욮 | 욯 |
| 0xc6b | 우 | 욱 | 욲 | 욳 | 운 | 욵 | 욶 | 욷 | 울 | 욹 | 욺 | 욻 | 욼 | 욽 | 욾 | 욿 |
| 0xc6c | 움 | 웁 | 웂 | 웃 | 웄 | 웅 | 웆 | 웇 | 웈 | 웉 | 웊 | 웋 | 워 | 웍 | 웎 | 웏 |
| 0xc6d | 원 | 웑 | 웒 | 웓 | 월 | 웕 | 웖 | 웗 | 웘 | 웙 | 웚 | 웛 | 웜 | 웝 | 웞 | 웟 |
| 0xc6e | 웠 | 웡 | 웢 | 웣 | 웤 | 웥 | 웦 | 웧 | 웨 | 웩 | 웪 | 웫 | 웬 | 웭 | 웮 | 웯 |
| 0xc6f | 웰 | 웱 | 웲 | 웳 | 웴 | 웵 | 웶 | 웷 | 웸 | 웹 | 웺 | 웻 | 웼 | 웽 | 웾 | 웿 |
| 0xc70 | 윀 | 윁 | 윂 | 윃 | 위 | 윅 | 윆 | 윇 | 윈 | 윉 | 윊 | 윋 | 윌 | 윍 | 윎 | 윏 |
| 0xc71 | 윐 | 윑 | 윒 | 윓 | 윔 | 윕 | 윖 | 윗 | 윘 | 윙 | 윚 | 윛 | 윜 | 윝 | 윞 | 윟 |
| 0xc72 | 유 | 육 | 윢 | 윣 | 윤 | 윥 | 윦 | 윧 | 율 | 윩 | 윪 | 윫 | 윬 | 윭 | 윮 | 윯 |
| 0xc73 | 윰 | 윱 | 윲 | 윳 | 윴 | 융 | 윶 | 윷 | 윸 | 윹 | 윺 | 윻 | 으 | 윽 | 윾 | 윿 |
| 0xc74 | 은 | 읁 | 읂 | 읃 | 을 | 읅 | 읆 | 읇 | 읈 | 읉 | 읊 | 읋 | 음 | 읍 | 읎 | 읏 |
| 0xc75 | 읐 | 응 | 읒 | 읓 | 읔 | 읕 | 읖 | 읗 | 의 | 읙 | 읚 | 읛 | 읜 | 읝 | 읞 | 읟 |
| 0xc76 | 읠 | 읡 | 읢 | 읣 | 읤 | 읥 | 읦 | 읧 | 읨 | 읩 | 읪 | 읫 | 읬 | 읭 | 읮 | 읯 |
| 0xc77 | 읰 | 읱 | 읲 | 읳 | 이 | 익 | 읶 | 읷 | 인 | 읹 | 읺 | 읻 | 일 | 읽 | 읾 | 읿 |
| 0xc78 | 잀 | 잁 | 잂 | 잃 | 임 | 입 | 잆 | 잇 | 있 | 잉 | 잊 | 잋 | 잌 | 잍 | 잎 | 잏 |
| 0xc79 | 자 | 작 | 잒 | 잓 | 잔 | 잕 | 잖 | 잗 | 잘 | 잙 | 잚 | 잛 | 잜 | 잝 | 잞 | 잟 |
| 0xc7a | 잠 | 잡 | 잢 | 잣 | 잤 | 장 | 잦 | 잧 | 잨 | 잩 | 잪 | 잫 | 재 | 잭 | 잮 | 잯 |
| 0xc7b | 잰 | 잱 | 잲 | 잳 | 잴 | 잵 | 잶 | 잷 | 잸 | 잹 | 잺 | 잻 | 잼 | 잽 | 잾 | 잿 |
| 0xc7c | 쟀 | 쟁 | 쟂 | 쟃 | 쟄 | 쟅 | 쟆 | 쟇 | 쟈 | 쟉 | 쟊 | 쟋 | 쟌 | 쟍 | 쟎 | 쟏 |
| 0xc7d | 쟐 | 쟑 | 쟒 | 쟓 | 쟔 | 쟕 | 쟖 | 쟗 | 쟘 | 쟙 | 쟚 | 쟛 | 쟜 | 쟝 | 쟞 | 쟟 |
| 0xc7e | 쟠 | 쟡 | 쟢 | 쟣 | 쟤 | 쟥 | 쟦 | 쟧 | 쟨 | 쟩 | 쟪 | 쟫 | 쟬 | 쟭 | 쟮 | 쟯 |
| 0xc7f | 쟰 | 쟱 | 쟲 | 쟳 | 쟴 | 쟵 | 쟶 | 쟷 | 쟸 | 쟹 | 쟺 | 쟻 | 쟼 | 쟽 | 쟾 | 쟿 |
| 0xc80 | 저 | 적 | 젂 | 젃 | 전 | 젅 | 젆 | 젇 | 절 | 젉 | 젊 | 젋 | 젌 | 젍 | 젎 | 젏 |
| 0xc81 | 점 | 접 | 젒 | 젓 | 젔 | 정 | 젖 | 젗 | 젘 | 젙 | 젚 | 젛 | 제 | 젝 | 젞 | 젟 |
| 0xc82 | 젠 | 젡 | 젢 | 젣 | 젤 | 젥 | 젦 | 젧 | 젨 | 젩 | 젪 | 젫 | 젬 | 젭 | 젮 | 젯 |
| 0xc83 | 젰 | 젱 | 젲 | 젳 | 젴 | 젵 | 젶 | 젷 | 져 | 젹 | 젺 | 젻 | 젼 | 젽 | 젾 | 젿 |
| 0xc84 | 졀 | 졁 | 졂 | 졃 | 졄 | 졅 | 졆 | 졇 | 졈 | 졉 | 졊 | 졋 | 졌 | 졍 | 졎 | 졏 |
| 0xc85 | 졐 | 졑 | 졒 | 졓 | 졔 | 졕 | 졖 | 졗 | 졘 | 졙 | 졚 | 졛 | 졜 | 졝 | 졞 | 졟 |
| 0xc86 | 졠 | 졡 | 졢 | 졣 | 졤 | 졥 | 졦 | 졧 | 졨 | 졩 | 졪 | 졫 | 졬 | 졭 | 졮 | 졯 |
| 0xc87 | 조 | 족 | 졲 | 졳 | 존 | 졵 | 졶 | 졷 | 졸 | 졹 | 졺 | 졻 | 졼 | 졽 | 졾 | 졿 |
| 0xc88 | 좀 | 좁 | 좂 | 좃 | 좄 | 종 | 좆 | 좇 | 좈 | 좉 | 좊 | 좋 | 좌 | 좍 | 좎 | 좏 |
| 0xc89 | 좐 | 좑 | 좒 | 좓 | 좔 | 좕 | 좖 | 좗 | 좘 | 좙 | 좚 | 좛 | 좜 | 좝 | 좞 | 좟 |
| 0xc8a | 좠 | 좡 | 좢 | 좣 | 좤 | 좥 | 좦 | 좧 | 좨 | 좩 | 좪 | 좫 | 좬 | 좭 | 좮 | 좯 |
| 0xc8b | 좰 | 좱 | 좲 | 좳 | 좴 | 좵 | 좶 | 좷 | 좸 | 좹 | 좺 | 좻 | 좼 | 좽 | 좾 | 좿 |
| 0xc8c | 죀 | 죁 | 죂 | 죃 | 죄 | 죅 | 죆 | 죇 | 죈 | 죉 | 죊 | 죋 | 죌 | 죍 | 죎 | 죏 |
| 0xc8d | 죐 | 죑 | 죒 | 죓 | 죔 | 죕 | 죖 | 죗 | 죘 | 죙 | 죚 | 죛 | 죜 | 죝 | 죞 | 죟 |
| 0xc8e | 죠 | 죡 | 죢 | 죣 | 죤 | 죥 | 죦 | 죧 | 죨 | 죩 | 죪 | 죫 | 죬 | 죭 | 죮 | 죯 |
| 0xc8f | 죰 | 죱 | 죲 | 죳 | 죴 | 죵 | 죶 | 죷 | 죸 | 죹 | 죺 | 죻 | 주 | 죽 | 죾 | 죿 |
| 0xc90 | 준 | 줁 | 줂 | 줃 | 줄 | 줅 | 줆 | 줇 | 줈 | 줉 | 줊 | 줋 | 줌 | 줍 | 줎 | 줏 |
| 0xc91 | 줐 | 중 | 줒 | 줓 | 줔 | 줕 | 줖 | 줗 | 줘 | 줙 | 줚 | 줛 | 줜 | 줝 | 줞 | 줟 |
| 0xc92 | 줠 | 줡 | 줢 | 줣 | 줤 | 줥 | 줦 | 줧 | 줨 | 줩 | 줪 | 줫 | 줬 | 줭 | 줮 | 줯 |
| 0xc93 | 줰 | 줱 | 줲 | 줳 | 줴 | 줵 | 줶 | 줷 | 줸 | 줹 | 줺 | 줻 | 줼 | 줽 | 줾 | 줿 |
| 0xc94 | 쥀 | 쥁 | 쥂 | 쥃 | 쥄 | 쥅 | 쥆 | 쥇 | 쥈 | 쥉 | 쥊 | 쥋 | 쥌 | 쥍 | 쥎 | 쥏 |
| 0xc95 | 쥐 | 쥑 | 쥒 | 쥓 | 쥔 | 쥕 | 쥖 | 쥗 | 쥘 | 쥙 | 쥚 | 쥛 | 쥜 | 쥝 | 쥞 | 쥟 |
| 0xc96 | 쥠 | 쥡 | 쥢 | 쥣 | 쥤 | 쥥 | 쥦 | 쥧 | 쥨 | 쥩 | 쥪 | 쥫 | 쥬 | 쥭 | 쥮 | 쥯 |
| 0xc97 | 쥰 | 쥱 | 쥲 | 쥳 | 쥴 | 쥵 | 쥶 | 쥷 | 쥸 | 쥹 | 쥺 | 쥻 | 쥼 | 쥽 | 쥾 | 쥿 |
| 0xc98 | 즀 | 즁 | 즂 | 즃 | 즄 | 즅 | 즆 | 즇 | 즈 | 즉 | 즊 | 즋 | 즌 | 즍 | 즎 | 즏 |
| 0xc99 | 즐 | 즑 | 즒 | 즓 | 즔 | 즕 | 즖 | 즗 | 즘 | 즙 | 즚 | 즛 | 즜 | 증 | 즞 | 즟 |
| 0xc9a | 즠 | 즡 | 즢 | 즣 | 즤 | 즥 | 즦 | 즧 | 즨 | 즩 | 즪 | 즫 | 즬 | 즭 | 즮 | 즯 |
| 0xc9b | 즰 | 즱 | 즲 | 즳 | 즴 | 즵 | 즶 | 즷 | 즸 | 즹 | 즺 | 즻 | 즼 | 즽 | 즾 | 즿 |
| 0xc9c | 지 | 직 | 짂 | 짃 | 진 | 짅 | 짆 | 짇 | 질 | 짉 | 짊 | 짋 | 짌 | 짍 | 짎 | 짏 |
| 0xc9d | 짐 | 집 | 짒 | 짓 | 짔 | 징 | 짖 | 짗 | 짘 | 짙 | 짚 | 짛 | 짜 | 짝 | 짞 | 짟 |
| 0xc9e | 짠 | 짡 | 짢 | 짣 | 짤 | 짥 | 짦 | 짧 | 짨 | 짩 | 짪 | 짫 | 짬 | 짭 | 짮 | 짯 |
| 0xc9f | 짰 | 짱 | 짲 | 짳 | 짴 | 짵 | 짶 | 짷 | 째 | 짹 | 짺 | 짻 | 짼 | 짽 | 짾 | 짿 |
| 0xca0 | 쨀 | 쨁 | 쨂 | 쨃 | 쨄 | 쨅 | 쨆 | 쨇 | 쨈 | 쨉 | 쨊 | 쨋 | 쨌 | 쨍 | 쨎 | 쨏 |
| 0xca1 | 쨐 | 쨑 | 쨒 | 쨓 | 쨔 | 쨕 | 쨖 | 쨗 | 쨘 | 쨙 | 쨚 | 쨛 | 쨜 | 쨝 | 쨞 | 쨟 |
| 0xca2 | 쨠 | 쨡 | 쨢 | 쨣 | 쨤 | 쨥 | 쨦 | 쨧 | 쨨 | 쨩 | 쨪 | 쨫 | 쨬 | 쨭 | 쨮 | 쨯 |
| 0xca3 | 쨰 | 쨱 | 쨲 | 쨳 | 쨴 | 쨵 | 쨶 | 쨷 | 쨸 | 쨹 | 쨺 | 쨻 | 쨼 | 쨽 | 쨾 | 쨿 |
| 0xca4 | 쩀 | 쩁 | 쩂 | 쩃 | 쩄 | 쩅 | 쩆 | 쩇 | 쩈 | 쩉 | 쩊 | 쩋 | 쩌 | 쩍 | 쩎 | 쩏 |
| 0xca5 | 쩐 | 쩑 | 쩒 | 쩓 | 쩔 | 쩕 | 쩖 | 쩗 | 쩘 | 쩙 | 쩚 | 쩛 | 쩜 | 쩝 | 쩞 | 쩟 |
| 0xca6 | 쩠 | 쩡 | 쩢 | 쩣 | 쩤 | 쩥 | 쩦 | 쩧 | 쩨 | 쩩 | 쩪 | 쩫 | 쩬 | 쩭 | 쩮 | 쩯 |
| 0xca7 | 쩰 | 쩱 | 쩲 | 쩳 | 쩴 | 쩵 | 쩶 | 쩷 | 쩸 | 쩹 | 쩺 | 쩻 | 쩼 | 쩽 | 쩾 | 쩿 |
| 0xca8 | 쪀 | 쪁 | 쪂 | 쪃 | 쪄 | 쪅 | 쪆 | 쪇 | 쪈 | 쪉 | 쪊 | 쪋 | 쪌 | 쪍 | 쪎 | 쪏 |
| 0xca9 | 쪐 | 쪑 | 쪒 | 쪓 | 쪔 | 쪕 | 쪖 | 쪗 | 쪘 | 쪙 | 쪚 | 쪛 | 쪜 | 쪝 | 쪞 | 쪟 |
| 0xcaa | 쪠 | 쪡 | 쪢 | 쪣 | 쪤 | 쪥 | 쪦 | 쪧 | 쪨 | 쪩 | 쪪 | 쪫 | 쪬 | 쪭 | 쪮 | 쪯 |
| 0xcab | 쪰 | 쪱 | 쪲 | 쪳 | 쪴 | 쪵 | 쪶 | 쪷 | 쪸 | 쪹 | 쪺 | 쪻 | 쪼 | 쪽 | 쪾 | 쪿 |
| 0xcac | 쫀 | 쫁 | 쫂 | 쫃 | 쫄 | 쫅 | 쫆 | 쫇 | 쫈 | 쫉 | 쫊 | 쫋 | 쫌 | 쫍 | 쫎 | 쫏 |
| 0xcad | 쫐 | 쫑 | 쫒 | 쫓 | 쫔 | 쫕 | 쫖 | 쫗 | 쫘 | 쫙 | 쫚 | 쫛 | 쫜 | 쫝 | 쫞 | 쫟 |
| 0xcae | 쫠 | 쫡 | 쫢 | 쫣 | 쫤 | 쫥 | 쫦 | 쫧 | 쫨 | 쫩 | 쫪 | 쫫 | 쫬 | 쫭 | 쫮 | 쫯 |
| 0xcaf | 쫰 | 쫱 | 쫲 | 쫳 | 쫴 | 쫵 | 쫶 | 쫷 | 쫸 | 쫹 | 쫺 | 쫻 | 쫼 | 쫽 | 쫾 | 쫿 |
| 0xcb0 | 쬀 | 쬁 | 쬂 | 쬃 | 쬄 | 쬅 | 쬆 | 쬇 | 쬈 | 쬉 | 쬊 | 쬋 | 쬌 | 쬍 | 쬎 | 쬏 |
| 0xcb1 | 쬐 | 쬑 | 쬒 | 쬓 | 쬔 | 쬕 | 쬖 | 쬗 | 쬘 | 쬙 | 쬚 | 쬛 | 쬜 | 쬝 | 쬞 | 쬟 |
| 0xcb2 | 쬠 | 쬡 | 쬢 | 쬣 | 쬤 | 쬥 | 쬦 | 쬧 | 쬨 | 쬩 | 쬪 | 쬫 | 쬬 | 쬭 | 쬮 | 쬯 |
| 0xcb3 | 쬰 | 쬱 | 쬲 | 쬳 | 쬴 | 쬵 | 쬶 | 쬷 | 쬸 | 쬹 | 쬺 | 쬻 | 쬼 | 쬽 | 쬾 | 쬿 |
| 0xcb4 | 쭀 | 쭁 | 쭂 | 쭃 | 쭄 | 쭅 | 쭆 | 쭇 | 쭈 | 쭉 | 쭊 | 쭋 | 쭌 | 쭍 | 쭎 | 쭏 |
| 0xcb5 | 쭐 | 쭑 | 쭒 | 쭓 | 쭔 | 쭕 | 쭖 | 쭗 | 쭘 | 쭙 | 쭚 | 쭛 | 쭜 | 쭝 | 쭞 | 쭟 |
| 0xcb6 | 쭠 | 쭡 | 쭢 | 쭣 | 쭤 | 쭥 | 쭦 | 쭧 | 쭨 | 쭩 | 쭪 | 쭫 | 쭬 | 쭭 | 쭮 | 쭯 |
| 0xcb7 | 쭰 | 쭱 | 쭲 | 쭳 | 쭴 | 쭵 | 쭶 | 쭷 | 쭸 | 쭹 | 쭺 | 쭻 | 쭼 | 쭽 | 쭾 | 쭿 |
| 0xcb8 | 쮀 | 쮁 | 쮂 | 쮃 | 쮄 | 쮅 | 쮆 | 쮇 | 쮈 | 쮉 | 쮊 | 쮋 | 쮌 | 쮍 | 쮎 | 쮏 |
| 0xcb9 | 쮐 | 쮑 | 쮒 | 쮓 | 쮔 | 쮕 | 쮖 | 쮗 | 쮘 | 쮙 | 쮚 | 쮛 | 쮜 | 쮝 | 쮞 | 쮟 |
| 0xcba | 쮠 | 쮡 | 쮢 | 쮣 | 쮤 | 쮥 | 쮦 | 쮧 | 쮨 | 쮩 | 쮪 | 쮫 | 쮬 | 쮭 | 쮮 | 쮯 |
| 0xcbb | 쮰 | 쮱 | 쮲 | 쮳 | 쮴 | 쮵 | 쮶 | 쮷 | 쮸 | 쮹 | 쮺 | 쮻 | 쮼 | 쮽 | 쮾 | 쮿 |
| 0xcbc | 쯀 | 쯁 | 쯂 | 쯃 | 쯄 | 쯅 | 쯆 | 쯇 | 쯈 | 쯉 | 쯊 | 쯋 | 쯌 | 쯍 | 쯎 | 쯏 |
| 0xcbd | 쯐 | 쯑 | 쯒 | 쯓 | 쯔 | 쯕 | 쯖 | 쯗 | 쯘 | 쯙 | 쯚 | 쯛 | 쯜 | 쯝 | 쯞 | 쯟 |
| 0xcbe | 쯠 | 쯡 | 쯢 | 쯣 | 쯤 | 쯥 | 쯦 | 쯧 | 쯨 | 쯩 | 쯪 | 쯫 | 쯬 | 쯭 | 쯮 | 쯯 |
| 0xcbf | 쯰 | 쯱 | 쯲 | 쯳 | 쯴 | 쯵 | 쯶 | 쯷 | 쯸 | 쯹 | 쯺 | 쯻 | 쯼 | 쯽 | 쯾 | 쯿 |
| 0xcc0 | 찀 | 찁 | 찂 | 찃 | 찄 | 찅 | 찆 | 찇 | 찈 | 찉 | 찊 | 찋 | 찌 | 찍 | 찎 | 찏 |
| 0xcc1 | 찐 | 찑 | 찒 | 찓 | 찔 | 찕 | 찖 | 찗 | 찘 | 찙 | 찚 | 찛 | 찜 | 찝 | 찞 | 찟 |
| 0xcc2 | 찠 | 찡 | 찢 | 찣 | 찤 | 찥 | 찦 | 찧 | 차 | 착 | 찪 | 찫 | 찬 | 찭 | 찮 | 찯 |
| 0xcc3 | 찰 | 찱 | 찲 | 찳 | 찴 | 찵 | 찶 | 찷 | 참 | 찹 | 찺 | 찻 | 찼 | 창 | 찾 | 찿 |
| 0xcc4 | 챀 | 챁 | 챂 | 챃 | 채 | 책 | 챆 | 챇 | 챈 | 챉 | 챊 | 챋 | 챌 | 챍 | 챎 | 챏 |
| 0xcc5 | 챐 | 챑 | 챒 | 챓 | 챔 | 챕 | 챖 | 챗 | 챘 | 챙 | 챚 | 챛 | 챜 | 챝 | 챞 | 챟 |
| 0xcc6 | 챠 | 챡 | 챢 | 챣 | 챤 | 챥 | 챦 | 챧 | 챨 | 챩 | 챪 | 챫 | 챬 | 챭 | 챮 | 챯 |
| 0xcc7 | 챰 | 챱 | 챲 | 챳 | 챴 | 챵 | 챶 | 챷 | 챸 | 챹 | 챺 | 챻 | 챼 | 챽 | 챾 | 챿 |
| 0xcc8 | 첀 | 첁 | 첂 | 첃 | 첄 | 첅 | 첆 | 첇 | 첈 | 첉 | 첊 | 첋 | 첌 | 첍 | 첎 | 첏 |
| 0xcc9 | 첐 | 첑 | 첒 | 첓 | 첔 | 첕 | 첖 | 첗 | 처 | 척 | 첚 | 첛 | 천 | 첝 | 첞 | 첟 |
| 0xcca | 철 | 첡 | 첢 | 첣 | 첤 | 첥 | 첦 | 첧 | 첨 | 첩 | 첪 | 첫 | 첬 | 청 | 첮 | 첯 |
| 0xccb | 첰 | 첱 | 첲 | 첳 | 체 | 첵 | 첶 | 첷 | 첸 | 첹 | 첺 | 첻 | 첼 | 첽 | 첾 | 첿 |
| 0xccc | 쳀 | 쳁 | 쳂 | 쳃 | 쳄 | 쳅 | 쳆 | 쳇 | 쳈 | 쳉 | 쳊 | 쳋 | 쳌 | 쳍 | 쳎 | 쳏 |
| 0xccd | 쳐 | 쳑 | 쳒 | 쳓 | 쳔 | 쳕 | 쳖 | 쳗 | 쳘 | 쳙 | 쳚 | 쳛 | 쳜 | 쳝 | 쳞 | 쳟 |
| 0xcce | 쳠 | 쳡 | 쳢 | 쳣 | 쳤 | 쳥 | 쳦 | 쳧 | 쳨 | 쳩 | 쳪 | 쳫 | 쳬 | 쳭 | 쳮 | 쳯 |
| 0xccf | 쳰 | 쳱 | 쳲 | 쳳 | 쳴 | 쳵 | 쳶 | 쳷 | 쳸 | 쳹 | 쳺 | 쳻 | 쳼 | 쳽 | 쳾 | 쳿 |
| 0xcd0 | 촀 | 촁 | 촂 | 촃 | 촄 | 촅 | 촆 | 촇 | 초 | 촉 | 촊 | 촋 | 촌 | 촍 | 촎 | 촏 |
| 0xcd1 | 촐 | 촑 | 촒 | 촓 | 촔 | 촕 | 촖 | 촗 | 촘 | 촙 | 촚 | 촛 | 촜 | 총 | 촞 | 촟 |
| 0xcd2 | 촠 | 촡 | 촢 | 촣 | 촤 | 촥 | 촦 | 촧 | 촨 | 촩 | 촪 | 촫 | 촬 | 촭 | 촮 | 촯 |
| 0xcd3 | 촰 | 촱 | 촲 | 촳 | 촴 | 촵 | 촶 | 촷 | 촸 | 촹 | 촺 | 촻 | 촼 | 촽 | 촾 | 촿 |
| 0xcd4 | 쵀 | 쵁 | 쵂 | 쵃 | 쵄 | 쵅 | 쵆 | 쵇 | 쵈 | 쵉 | 쵊 | 쵋 | 쵌 | 쵍 | 쵎 | 쵏 |
| 0xcd5 | 쵐 | 쵑 | 쵒 | 쵓 | 쵔 | 쵕 | 쵖 | 쵗 | 쵘 | 쵙 | 쵚 | 쵛 | 최 | 쵝 | 쵞 | 쵟 |
| 0xcd6 | 쵠 | 쵡 | 쵢 | 쵣 | 쵤 | 쵥 | 쵦 | 쵧 | 쵨 | 쵩 | 쵪 | 쵫 | 쵬 | 쵭 | 쵮 | 쵯 |
| 0xcd7 | 쵰 | 쵱 | 쵲 | 쵳 | 쵴 | 쵵 | 쵶 | 쵷 | 쵸 | 쵹 | 쵺 | 쵻 | 쵼 | 쵽 | 쵾 | 쵿 |
| 0xcd8 | 춀 | 춁 | 춂 | 춃 | 춄 | 춅 | 춆 | 춇 | 춈 | 춉 | 춊 | 춋 | 춌 | 춍 | 춎 | 춏 |
| 0xcd9 | 춐 | 춑 | 춒 | 춓 | 추 | 축 | 춖 | 춗 | 춘 | 춙 | 춚 | 춛 | 출 | 춝 | 춞 | 춟 |
| 0xcda | 춠 | 춡 | 춢 | 춣 | 춤 | 춥 | 춦 | 춧 | 춨 | 충 | 춪 | 춫 | 춬 | 춭 | 춮 | 춯 |
| 0xcdb | 춰 | 춱 | 춲 | 춳 | 춴 | 춵 | 춶 | 춷 | 춸 | 춹 | 춺 | 춻 | 춼 | 춽 | 춾 | 춿 |
| 0xcdc | 췀 | 췁 | 췂 | 췃 | 췄 | 췅 | 췆 | 췇 | 췈 | 췉 | 췊 | 췋 | 췌 | 췍 | 췎 | 췏 |
| 0xcdd | 췐 | 췑 | 췒 | 췓 | 췔 | 췕 | 췖 | 췗 | 췘 | 췙 | 췚 | 췛 | 췜 | 췝 | 췞 | 췟 |
| 0xcde | 췠 | 췡 | 췢 | 췣 | 췤 | 췥 | 췦 | 췧 | 취 | 췩 | 췪 | 췫 | 췬 | 췭 | 췮 | 췯 |
| 0xcdf | 췰 | 췱 | 췲 | 췳 | 췴 | 췵 | 췶 | 췷 | 췸 | 췹 | 췺 | 췻 | 췼 | 췽 | 췾 | 췿 |
| 0xce0 | 츀 | 츁 | 츂 | 츃 | 츄 | 츅 | 츆 | 츇 | 츈 | 츉 | 츊 | 츋 | 츌 | 츍 | 츎 | 츏 |
| 0xce1 | 츐 | 츑 | 츒 | 츓 | 츔 | 츕 | 츖 | 츗 | 츘 | 츙 | 츚 | 츛 | 츜 | 츝 | 츞 | 츟 |
| 0xce2 | 츠 | 측 | 츢 | 츣 | 츤 | 츥 | 츦 | 츧 | 츨 | 츩 | 츪 | 츫 | 츬 | 츭 | 츮 | 츯 |
| 0xce3 | 츰 | 츱 | 츲 | 츳 | 츴 | 층 | 츶 | 츷 | 츸 | 츹 | 츺 | 츻 | 츼 | 츽 | 츾 | 츿 |
| 0xce4 | 칀 | 칁 | 칂 | 칃 | 칄 | 칅 | 칆 | 칇 | 칈 | 칉 | 칊 | 칋 | 칌 | 칍 | 칎 | 칏 |
| 0xce5 | 칐 | 칑 | 칒 | 칓 | 칔 | 칕 | 칖 | 칗 | 치 | 칙 | 칚 | 칛 | 친 | 칝 | 칞 | 칟 |
| 0xce6 | 칠 | 칡 | 칢 | 칣 | 칤 | 칥 | 칦 | 칧 | 침 | 칩 | 칪 | 칫 | 칬 | 칭 | 칮 | 칯 |
| 0xce7 | 칰 | 칱 | 칲 | 칳 | 카 | 칵 | 칶 | 칷 | 칸 | 칹 | 칺 | 칻 | 칼 | 칽 | 칾 | 칿 |
| 0xce8 | 캀 | 캁 | 캂 | 캃 | 캄 | 캅 | 캆 | 캇 | 캈 | 캉 | 캊 | 캋 | 캌 | 캍 | 캎 | 캏 |
| 0xce9 | 캐 | 캑 | 캒 | 캓 | 캔 | 캕 | 캖 | 캗 | 캘 | 캙 | 캚 | 캛 | 캜 | 캝 | 캞 | 캟 |
| 0xcea | 캠 | 캡 | 캢 | 캣 | 캤 | 캥 | 캦 | 캧 | 캨 | 캩 | 캪 | 캫 | 캬 | 캭 | 캮 | 캯 |
| 0xceb | 캰 | 캱 | 캲 | 캳 | 캴 | 캵 | 캶 | 캷 | 캸 | 캹 | 캺 | 캻 | 캼 | 캽 | 캾 | 캿 |
| 0xcec | 컀 | 컁 | 컂 | 컃 | 컄 | 컅 | 컆 | 컇 | 컈 | 컉 | 컊 | 컋 | 컌 | 컍 | 컎 | 컏 |
| 0xced | 컐 | 컑 | 컒 | 컓 | 컔 | 컕 | 컖 | 컗 | 컘 | 컙 | 컚 | 컛 | 컜 | 컝 | 컞 | 컟 |
| 0xcee | 컠 | 컡 | 컢 | 컣 | 커 | 컥 | 컦 | 컧 | 컨 | 컩 | 컪 | 컫 | 컬 | 컭 | 컮 | 컯 |
| 0xcef | 컰 | 컱 | 컲 | 컳 | 컴 | 컵 | 컶 | 컷 | 컸 | 컹 | 컺 | 컻 | 컼 | 컽 | 컾 | 컿 |
| 0xcf0 | 케 | 켁 | 켂 | 켃 | 켄 | 켅 | 켆 | 켇 | 켈 | 켉 | 켊 | 켋 | 켌 | 켍 | 켎 | 켏 |
| 0xcf1 | 켐 | 켑 | 켒 | 켓 | 켔 | 켕 | 켖 | 켗 | 켘 | 켙 | 켚 | 켛 | 켜 | 켝 | 켞 | 켟 |
| 0xcf2 | 켠 | 켡 | 켢 | 켣 | 켤 | 켥 | 켦 | 켧 | 켨 | 켩 | 켪 | 켫 | 켬 | 켭 | 켮 | 켯 |
| 0xcf3 | 켰 | 켱 | 켲 | 켳 | 켴 | 켵 | 켶 | 켷 | 켸 | 켹 | 켺 | 켻 | 켼 | 켽 | 켾 | 켿 |
| 0xcf4 | 콀 | 콁 | 콂 | 콃 | 콄 | 콅 | 콆 | 콇 | 콈 | 콉 | 콊 | 콋 | 콌 | 콍 | 콎 | 콏 |
| 0xcf5 | 콐 | 콑 | 콒 | 콓 | 코 | 콕 | 콖 | 콗 | 콘 | 콙 | 콚 | 콛 | 콜 | 콝 | 콞 | 콟 |
| 0xcf6 | 콠 | 콡 | 콢 | 콣 | 콤 | 콥 | 콦 | 콧 | 콨 | 콩 | 콪 | 콫 | 콬 | 콭 | 콮 | 콯 |
| 0xcf7 | 콰 | 콱 | 콲 | 콳 | 콴 | 콵 | 콶 | 콷 | 콸 | 콹 | 콺 | 콻 | 콼 | 콽 | 콾 | 콿 |
| 0xcf8 | 쾀 | 쾁 | 쾂 | 쾃 | 쾄 | 쾅 | 쾆 | 쾇 | 쾈 | 쾉 | 쾊 | 쾋 | 쾌 | 쾍 | 쾎 | 쾏 |
| 0xcf9 | 쾐 | 쾑 | 쾒 | 쾓 | 쾔 | 쾕 | 쾖 | 쾗 | 쾘 | 쾙 | 쾚 | 쾛 | 쾜 | 쾝 | 쾞 | 쾟 |
| 0xcfa | 쾠 | 쾡 | 쾢 | 쾣 | 쾤 | 쾥 | 쾦 | 쾧 | 쾨 | 쾩 | 쾪 | 쾫 | 쾬 | 쾭 | 쾮 | 쾯 |
| 0xcfb | 쾰 | 쾱 | 쾲 | 쾳 | 쾴 | 쾵 | 쾶 | 쾷 | 쾸 | 쾹 | 쾺 | 쾻 | 쾼 | 쾽 | 쾾 | 쾿 |
| 0xcfc | 쿀 | 쿁 | 쿂 | 쿃 | 쿄 | 쿅 | 쿆 | 쿇 | 쿈 | 쿉 | 쿊 | 쿋 | 쿌 | 쿍 | 쿎 | 쿏 |
| 0xcfd | 쿐 | 쿑 | 쿒 | 쿓 | 쿔 | 쿕 | 쿖 | 쿗 | 쿘 | 쿙 | 쿚 | 쿛 | 쿜 | 쿝 | 쿞 | 쿟 |
| 0xcfe | 쿠 | 쿡 | 쿢 | 쿣 | 쿤 | 쿥 | 쿦 | 쿧 | 쿨 | 쿩 | 쿪 | 쿫 | 쿬 | 쿭 | 쿮 | 쿯 |
| 0xcff | 쿰 | 쿱 | 쿲 | 쿳 | 쿴 | 쿵 | 쿶 | 쿷 | 쿸 | 쿹 | 쿺 | 쿻 | 쿼 | 쿽 | 쿾 | 쿿 |
| 0xd00 | 퀀 | 퀁 | 퀂 | 퀃 | 퀄 | 퀅 | 퀆 | 퀇 | 퀈 | 퀉 | 퀊 | 퀋 | 퀌 | 퀍 | 퀎 | 퀏 |
| 0xd01 | 퀐 | 퀑 | 퀒 | 퀓 | 퀔 | 퀕 | 퀖 | 퀗 | 퀘 | 퀙 | 퀚 | 퀛 | 퀜 | 퀝 | 퀞 | 퀟 |
| 0xd02 | 퀠 | 퀡 | 퀢 | 퀣 | 퀤 | 퀥 | 퀦 | 퀧 | 퀨 | 퀩 | 퀪 | 퀫 | 퀬 | 퀭 | 퀮 | 퀯 |
| 0xd03 | 퀰 | 퀱 | 퀲 | 퀳 | 퀴 | 퀵 | 퀶 | 퀷 | 퀸 | 퀹 | 퀺 | 퀻 | 퀼 | 퀽 | 퀾 | 퀿 |
| 0xd04 | 큀 | 큁 | 큂 | 큃 | 큄 | 큅 | 큆 | 큇 | 큈 | 큉 | 큊 | 큋 | 큌 | 큍 | 큎 | 큏 |
| 0xd05 | 큐 | 큑 | 큒 | 큓 | 큔 | 큕 | 큖 | 큗 | 큘 | 큙 | 큚 | 큛 | 큜 | 큝 | 큞 | 큟 |
| 0xd06 | 큠 | 큡 | 큢 | 큣 | 큤 | 큥 | 큦 | 큧 | 큨 | 큩 | 큪 | 큫 | 크 | 큭 | 큮 | 큯 |
| 0xd07 | 큰 | 큱 | 큲 | 큳 | 클 | 큵 | 큶 | 큷 | 큸 | 큹 | 큺 | 큻 | 큼 | 큽 | 큾 | 큿 |
| 0xd08 | 킀 | 킁 | 킂 | 킃 | 킄 | 킅 | 킆 | 킇 | 킈 | 킉 | 킊 | 킋 | 킌 | 킍 | 킎 | 킏 |
| 0xd09 | 킐 | 킑 | 킒 | 킓 | 킔 | 킕 | 킖 | 킗 | 킘 | 킙 | 킚 | 킛 | 킜 | 킝 | 킞 | 킟 |
| 0xd0a | 킠 | 킡 | 킢 | 킣 | 키 | 킥 | 킦 | 킧 | 킨 | 킩 | 킪 | 킫 | 킬 | 킭 | 킮 | 킯 |
| 0xd0b | 킰 | 킱 | 킲 | 킳 | 킴 | 킵 | 킶 | 킷 | 킸 | 킹 | 킺 | 킻 | 킼 | 킽 | 킾 | 킿 |
| 0xd0c | 타 | 탁 | 탂 | 탃 | 탄 | 탅 | 탆 | 탇 | 탈 | 탉 | 탊 | 탋 | 탌 | 탍 | 탎 | 탏 |
| 0xd0d | 탐 | 탑 | 탒 | 탓 | 탔 | 탕 | 탖 | 탗 | 탘 | 탙 | 탚 | 탛 | 태 | 택 | 탞 | 탟 |
| 0xd0e | 탠 | 탡 | 탢 | 탣 | 탤 | 탥 | 탦 | 탧 | 탨 | 탩 | 탪 | 탫 | 탬 | 탭 | 탮 | 탯 |
| 0xd0f | 탰 | 탱 | 탲 | 탳 | 탴 | 탵 | 탶 | 탷 | 탸 | 탹 | 탺 | 탻 | 탼 | 탽 | 탾 | 탿 |
| 0xd10 | 턀 | 턁 | 턂 | 턃 | 턄 | 턅 | 턆 | 턇 | 턈 | 턉 | 턊 | 턋 | 턌 | 턍 | 턎 | 턏 |
| 0xd11 | 턐 | 턑 | 턒 | 턓 | 턔 | 턕 | 턖 | 턗 | 턘 | 턙 | 턚 | 턛 | 턜 | 턝 | 턞 | 턟 |
| 0xd12 | 턠 | 턡 | 턢 | 턣 | 턤 | 턥 | 턦 | 턧 | 턨 | 턩 | 턪 | 턫 | 턬 | 턭 | 턮 | 턯 |
| 0xd13 | 터 | 턱 | 턲 | 턳 | 턴 | 턵 | 턶 | 턷 | 털 | 턹 | 턺 | 턻 | 턼 | 턽 | 턾 | 턿 |
| 0xd14 | 텀 | 텁 | 텂 | 텃 | 텄 | 텅 | 텆 | 텇 | 텈 | 텉 | 텊 | 텋 | 테 | 텍 | 텎 | 텏 |
| 0xd15 | 텐 | 텑 | 텒 | 텓 | 텔 | 텕 | 텖 | 텗 | 텘 | 텙 | 텚 | 텛 | 템 | 텝 | 텞 | 텟 |
| 0xd16 | 텠 | 텡 | 텢 | 텣 | 텤 | 텥 | 텦 | 텧 | 텨 | 텩 | 텪 | 텫 | 텬 | 텭 | 텮 | 텯 |
| 0xd17 | 텰 | 텱 | 텲 | 텳 | 텴 | 텵 | 텶 | 텷 | 텸 | 텹 | 텺 | 텻 | 텼 | 텽 | 텾 | 텿 |
| 0xd18 | 톀 | 톁 | 톂 | 톃 | 톄 | 톅 | 톆 | 톇 | 톈 | 톉 | 톊 | 톋 | 톌 | 톍 | 톎 | 톏 |
| 0xd19 | 톐 | 톑 | 톒 | 톓 | 톔 | 톕 | 톖 | 톗 | 톘 | 톙 | 톚 | 톛 | 톜 | 톝 | 톞 | 톟 |
| 0xd1a | 토 | 톡 | 톢 | 톣 | 톤 | 톥 | 톦 | 톧 | 톨 | 톩 | 톪 | 톫 | 톬 | 톭 | 톮 | 톯 |
| 0xd1b | 톰 | 톱 | 톲 | 톳 | 톴 | 통 | 톶 | 톷 | 톸 | 톹 | 톺 | 톻 | 톼 | 톽 | 톾 | 톿 |
| 0xd1c | 퇀 | 퇁 | 퇂 | 퇃 | 퇄 | 퇅 | 퇆 | 퇇 | 퇈 | 퇉 | 퇊 | 퇋 | 퇌 | 퇍 | 퇎 | 퇏 |
| 0xd1d | 퇐 | 퇑 | 퇒 | 퇓 | 퇔 | 퇕 | 퇖 | 퇗 | 퇘 | 퇙 | 퇚 | 퇛 | 퇜 | 퇝 | 퇞 | 퇟 |
| 0xd1e | 퇠 | 퇡 | 퇢 | 퇣 | 퇤 | 퇥 | 퇦 | 퇧 | 퇨 | 퇩 | 퇪 | 퇫 | 퇬 | 퇭 | 퇮 | 퇯 |
| 0xd1f | 퇰 | 퇱 | 퇲 | 퇳 | 퇴 | 퇵 | 퇶 | 퇷 | 퇸 | 퇹 | 퇺 | 퇻 | 퇼 | 퇽 | 퇾 | 퇿 |
| 0xd20 | 툀 | 툁 | 툂 | 툃 | 툄 | 툅 | 툆 | 툇 | 툈 | 툉 | 툊 | 툋 | 툌 | 툍 | 툎 | 툏 |
| 0xd21 | 툐 | 툑 | 툒 | 툓 | 툔 | 툕 | 툖 | 툗 | 툘 | 툙 | 툚 | 툛 | 툜 | 툝 | 툞 | 툟 |
| 0xd22 | 툠 | 툡 | 툢 | 툣 | 툤 | 툥 | 툦 | 툧 | 툨 | 툩 | 툪 | 툫 | 투 | 툭 | 툮 | 툯 |
| 0xd23 | 툰 | 툱 | 툲 | 툳 | 툴 | 툵 | 툶 | 툷 | 툸 | 툹 | 툺 | 툻 | 툼 | 툽 | 툾 | 툿 |
| 0xd24 | 퉀 | 퉁 | 퉂 | 퉃 | 퉄 | 퉅 | 퉆 | 퉇 | 퉈 | 퉉 | 퉊 | 퉋 | 퉌 | 퉍 | 퉎 | 퉏 |
| 0xd25 | 퉐 | 퉑 | 퉒 | 퉓 | 퉔 | 퉕 | 퉖 | 퉗 | 퉘 | 퉙 | 퉚 | 퉛 | 퉜 | 퉝 | 퉞 | 퉟 |
| 0xd26 | 퉠 | 퉡 | 퉢 | 퉣 | 퉤 | 퉥 | 퉦 | 퉧 | 퉨 | 퉩 | 퉪 | 퉫 | 퉬 | 퉭 | 퉮 | 퉯 |
| 0xd27 | 퉰 | 퉱 | 퉲 | 퉳 | 퉴 | 퉵 | 퉶 | 퉷 | 퉸 | 퉹 | 퉺 | 퉻 | 퉼 | 퉽 | 퉾 | 퉿 |
| 0xd28 | 튀 | 튁 | 튂 | 튃 | 튄 | 튅 | 튆 | 튇 | 튈 | 튉 | 튊 | 튋 | 튌 | 튍 | 튎 | 튏 |
| 0xd29 | 튐 | 튑 | 튒 | 튓 | 튔 | 튕 | 튖 | 튗 | 튘 | 튙 | 튚 | 튛 | 튜 | 튝 | 튞 | 튟 |
| 0xd2a | 튠 | 튡 | 튢 | 튣 | 튤 | 튥 | 튦 | 튧 | 튨 | 튩 | 튪 | 튫 | 튬 | 튭 | 튮 | 튯 |
| 0xd2b | 튰 | 튱 | 튲 | 튳 | 튴 | 튵 | 튶 | 튷 | 트 | 특 | 튺 | 튻 | 튼 | 튽 | 튾 | 튿 |
| 0xd2c | 틀 | 틁 | 틂 | 틃 | 틄 | 틅 | 틆 | 틇 | 틈 | 틉 | 틊 | 틋 | 틌 | 틍 | 틎 | 틏 |
| 0xd2d | 틐 | 틑 | 틒 | 틓 | 틔 | 틕 | 틖 | 틗 | 틘 | 틙 | 틚 | 틛 | 틜 | 틝 | 틞 | 틟 |
| 0xd2e | 틠 | 틡 | 틢 | 틣 | 틤 | 틥 | 틦 | 틧 | 틨 | 틩 | 틪 | 틫 | 틬 | 틭 | 틮 | 틯 |
| 0xd2f | 티 | 틱 | 틲 | 틳 | 틴 | 틵 | 틶 | 틷 | 틸 | 틹 | 틺 | 틻 | 틼 | 틽 | 틾 | 틿 |
| 0xd30 | 팀 | 팁 | 팂 | 팃 | 팄 | 팅 | 팆 | 팇 | 팈 | 팉 | 팊 | 팋 | 파 | 팍 | 팎 | 팏 |
| 0xd31 | 판 | 팑 | 팒 | 팓 | 팔 | 팕 | 팖 | 팗 | 팘 | 팙 | 팚 | 팛 | 팜 | 팝 | 팞 | 팟 |
| 0xd32 | 팠 | 팡 | 팢 | 팣 | 팤 | 팥 | 팦 | 팧 | 패 | 팩 | 팪 | 팫 | 팬 | 팭 | 팮 | 팯 |
| 0xd33 | 팰 | 팱 | 팲 | 팳 | 팴 | 팵 | 팶 | 팷 | 팸 | 팹 | 팺 | 팻 | 팼 | 팽 | 팾 | 팿 |
| 0xd34 | 퍀 | 퍁 | 퍂 | 퍃 | 퍄 | 퍅 | 퍆 | 퍇 | 퍈 | 퍉 | 퍊 | 퍋 | 퍌 | 퍍 | 퍎 | 퍏 |
| 0xd35 | 퍐 | 퍑 | 퍒 | 퍓 | 퍔 | 퍕 | 퍖 | 퍗 | 퍘 | 퍙 | 퍚 | 퍛 | 퍜 | 퍝 | 퍞 | 퍟 |
| 0xd36 | 퍠 | 퍡 | 퍢 | 퍣 | 퍤 | 퍥 | 퍦 | 퍧 | 퍨 | 퍩 | 퍪 | 퍫 | 퍬 | 퍭 | 퍮 | 퍯 |
| 0xd37 | 퍰 | 퍱 | 퍲 | 퍳 | 퍴 | 퍵 | 퍶 | 퍷 | 퍸 | 퍹 | 퍺 | 퍻 | 퍼 | 퍽 | 퍾 | 퍿 |
| 0xd38 | 펀 | 펁 | 펂 | 펃 | 펄 | 펅 | 펆 | 펇 | 펈 | 펉 | 펊 | 펋 | 펌 | 펍 | 펎 | 펏 |
| 0xd39 | 펐 | 펑 | 펒 | 펓 | 펔 | 펕 | 펖 | 펗 | 페 | 펙 | 펚 | 펛 | 펜 | 펝 | 펞 | 펟 |
| 0xd3a | 펠 | 펡 | 펢 | 펣 | 펤 | 펥 | 펦 | 펧 | 펨 | 펩 | 펪 | 펫 | 펬 | 펭 | 펮 | 펯 |
| 0xd3b | 펰 | 펱 | 펲 | 펳 | 펴 | 펵 | 펶 | 펷 | 편 | 펹 | 펺 | 펻 | 펼 | 펽 | 펾 | 펿 |
| 0xd3c | 폀 | 폁 | 폂 | 폃 | 폄 | 폅 | 폆 | 폇 | 폈 | 평 | 폊 | 폋 | 폌 | 폍 | 폎 | 폏 |
| 0xd3d | 폐 | 폑 | 폒 | 폓 | 폔 | 폕 | 폖 | 폗 | 폘 | 폙 | 폚 | 폛 | 폜 | 폝 | 폞 | 폟 |
| 0xd3e | 폠 | 폡 | 폢 | 폣 | 폤 | 폥 | 폦 | 폧 | 폨 | 폩 | 폪 | 폫 | 포 | 폭 | 폮 | 폯 |
| 0xd3f | 폰 | 폱 | 폲 | 폳 | 폴 | 폵 | 폶 | 폷 | 폸 | 폹 | 폺 | 폻 | 폼 | 폽 | 폾 | 폿 |
| 0xd40 | 퐀 | 퐁 | 퐂 | 퐃 | 퐄 | 퐅 | 퐆 | 퐇 | 퐈 | 퐉 | 퐊 | 퐋 | 퐌 | 퐍 | 퐎 | 퐏 |
| 0xd41 | 퐐 | 퐑 | 퐒 | 퐓 | 퐔 | 퐕 | 퐖 | 퐗 | 퐘 | 퐙 | 퐚 | 퐛 | 퐜 | 퐝 | 퐞 | 퐟 |
| 0xd42 | 퐠 | 퐡 | 퐢 | 퐣 | 퐤 | 퐥 | 퐦 | 퐧 | 퐨 | 퐩 | 퐪 | 퐫 | 퐬 | 퐭 | 퐮 | 퐯 |
| 0xd43 | 퐰 | 퐱 | 퐲 | 퐳 | 퐴 | 퐵 | 퐶 | 퐷 | 퐸 | 퐹 | 퐺 | 퐻 | 퐼 | 퐽 | 퐾 | 퐿 |
| 0xd44 | 푀 | 푁 | 푂 | 푃 | 푄 | 푅 | 푆 | 푇 | 푈 | 푉 | 푊 | 푋 | 푌 | 푍 | 푎 | 푏 |
| 0xd45 | 푐 | 푑 | 푒 | 푓 | 푔 | 푕 | 푖 | 푗 | 푘 | 푙 | 푚 | 푛 | 표 | 푝 | 푞 | 푟 |
| 0xd46 | 푠 | 푡 | 푢 | 푣 | 푤 | 푥 | 푦 | 푧 | 푨 | 푩 | 푪 | 푫 | 푬 | 푭 | 푮 | 푯 |
| 0xd47 | 푰 | 푱 | 푲 | 푳 | 푴 | 푵 | 푶 | 푷 | 푸 | 푹 | 푺 | 푻 | 푼 | 푽 | 푾 | 푿 |
| 0xd48 | 풀 | 풁 | 풂 | 풃 | 풄 | 풅 | 풆 | 풇 | 품 | 풉 | 풊 | 풋 | 풌 | 풍 | 풎 | 풏 |
| 0xd49 | 풐 | 풑 | 풒 | 풓 | 풔 | 풕 | 풖 | 풗 | 풘 | 풙 | 풚 | 풛 | 풜 | 풝 | 풞 | 풟 |
| 0xd4a | 풠 | 풡 | 풢 | 풣 | 풤 | 풥 | 풦 | 풧 | 풨 | 풩 | 풪 | 풫 | 풬 | 풭 | 풮 | 풯 |
| 0xd4b | 풰 | 풱 | 풲 | 풳 | 풴 | 풵 | 풶 | 풷 | 풸 | 풹 | 풺 | 풻 | 풼 | 풽 | 풾 | 풿 |
| 0xd4c | 퓀 | 퓁 | 퓂 | 퓃 | 퓄 | 퓅 | 퓆 | 퓇 | 퓈 | 퓉 | 퓊 | 퓋 | 퓌 | 퓍 | 퓎 | 퓏 |
| 0xd4d | 퓐 | 퓑 | 퓒 | 퓓 | 퓔 | 퓕 | 퓖 | 퓗 | 퓘 | 퓙 | 퓚 | 퓛 | 퓜 | 퓝 | 퓞 | 퓟 |
| 0xd4e | 퓠 | 퓡 | 퓢 | 퓣 | 퓤 | 퓥 | 퓦 | 퓧 | 퓨 | 퓩 | 퓪 | 퓫 | 퓬 | 퓭 | 퓮 | 퓯 |
| 0xd4f | 퓰 | 퓱 | 퓲 | 퓳 | 퓴 | 퓵 | 퓶 | 퓷 | 퓸 | 퓹 | 퓺 | 퓻 | 퓼 | 퓽 | 퓾 | 퓿 |
| 0xd50 | 픀 | 픁 | 픂 | 픃 | 프 | 픅 | 픆 | 픇 | 픈 | 픉 | 픊 | 픋 | 플 | 픍 | 픎 | 픏 |
| 0xd51 | 픐 | 픑 | 픒 | 픓 | 픔 | 픕 | 픖 | 픗 | 픘 | 픙 | 픚 | 픛 | 픜 | 픝 | 픞 | 픟 |
| 0xd52 | 픠 | 픡 | 픢 | 픣 | 픤 | 픥 | 픦 | 픧 | 픨 | 픩 | 픪 | 픫 | 픬 | 픭 | 픮 | 픯 |
| 0xd53 | 픰 | 픱 | 픲 | 픳 | 픴 | 픵 | 픶 | 픷 | 픸 | 픹 | 픺 | 픻 | 피 | 픽 | 픾 | 픿 |
| 0xd54 | 핀 | 핁 | 핂 | 핃 | 필 | 핅 | 핆 | 핇 | 핈 | 핉 | 핊 | 핋 | 핌 | 핍 | 핎 | 핏 |
| 0xd55 | 핐 | 핑 | 핒 | 핓 | 핔 | 핕 | 핖 | 핗 | 하 | 학 | 핚 | 핛 | 한 | 핝 | 핞 | 핟 |
| 0xd56 | 할 | 핡 | 핢 | 핣 | 핤 | 핥 | 핦 | 핧 | 함 | 합 | 핪 | 핫 | 핬 | 항 | 핮 | 핯 |
| 0xd57 | 핰 | 핱 | 핲 | 핳 | 해 | 핵 | 핶 | 핷 | 핸 | 핹 | 핺 | 핻 | 핼 | 핽 | 핾 | 핿 |
| 0xd58 | 햀 | 햁 | 햂 | 햃 | 햄 | 햅 | 햆 | 햇 | 했 | 행 | 햊 | 햋 | 햌 | 햍 | 햎 | 햏 |
| 0xd59 | 햐 | 햑 | 햒 | 햓 | 햔 | 햕 | 햖 | 햗 | 햘 | 햙 | 햚 | 햛 | 햜 | 햝 | 햞 | 햟 |
| 0xd5a | 햠 | 햡 | 햢 | 햣 | 햤 | 향 | 햦 | 햧 | 햨 | 햩 | 햪 | 햫 | 햬 | 햭 | 햮 | 햯 |
| 0xd5b | 햰 | 햱 | 햲 | 햳 | 햴 | 햵 | 햶 | 햷 | 햸 | 햹 | 햺 | 햻 | 햼 | 햽 | 햾 | 햿 |
| 0xd5c | 헀 | 헁 | 헂 | 헃 | 헄 | 헅 | 헆 | 헇 | 허 | 헉 | 헊 | 헋 | 헌 | 헍 | 헎 | 헏 |
| 0xd5d | 헐 | 헑 | 헒 | 헓 | 헔 | 헕 | 헖 | 헗 | 험 | 헙 | 헚 | 헛 | 헜 | 헝 | 헞 | 헟 |
| 0xd5e | 헠 | 헡 | 헢 | 헣 | 헤 | 헥 | 헦 | 헧 | 헨 | 헩 | 헪 | 헫 | 헬 | 헭 | 헮 | 헯 |
| 0xd5f | 헰 | 헱 | 헲 | 헳 | 헴 | 헵 | 헶 | 헷 | 헸 | 헹 | 헺 | 헻 | 헼 | 헽 | 헾 | 헿 |
| 0xd60 | 혀 | 혁 | 혂 | 혃 | 현 | 혅 | 혆 | 혇 | 혈 | 혉 | 혊 | 혋 | 혌 | 혍 | 혎 | 혏 |
| 0xd61 | 혐 | 협 | 혒 | 혓 | 혔 | 형 | 혖 | 혗 | 혘 | 혙 | 혚 | 혛 | 혜 | 혝 | 혞 | 혟 |
| 0xd62 | 혠 | 혡 | 혢 | 혣 | 혤 | 혥 | 혦 | 혧 | 혨 | 혩 | 혪 | 혫 | 혬 | 혭 | 혮 | 혯 |
| 0xd63 | 혰 | 혱 | 혲 | 혳 | 혴 | 혵 | 혶 | 혷 | 호 | 혹 | 혺 | 혻 | 혼 | 혽 | 혾 | 혿 |
| 0xd64 | 홀 | 홁 | 홂 | 홃 | 홄 | 홅 | 홆 | 홇 | 홈 | 홉 | 홊 | 홋 | 홌 | 홍 | 홎 | 홏 |
| 0xd65 | 홐 | 홑 | 홒 | 홓 | 화 | 확 | 홖 | 홗 | 환 | 홙 | 홚 | 홛 | 활 | 홝 | 홞 | 홟 |
| 0xd66 | 홠 | 홡 | 홢 | 홣 | 홤 | 홥 | 홦 | 홧 | 홨 | 황 | 홪 | 홫 | 홬 | 홭 | 홮 | 홯 |
| 0xd67 | 홰 | 홱 | 홲 | 홳 | 홴 | 홵 | 홶 | 홷 | 홸 | 홹 | 홺 | 홻 | 홼 | 홽 | 홾 | 홿 |
| 0xd68 | 횀 | 횁 | 횂 | 횃 | 횄 | 횅 | 횆 | 횇 | 횈 | 횉 | 횊 | 횋 | 회 | 획 | 횎 | 횏 |
| 0xd69 | 횐 | 횑 | 횒 | 횓 | 횔 | 횕 | 횖 | 횗 | 횘 | 횙 | 횚 | 횛 | 횜 | 횝 | 횞 | 횟 |
| 0xd6a | 횠 | 횡 | 횢 | 횣 | 횤 | 횥 | 횦 | 횧 | 효 | 횩 | 횪 | 횫 | 횬 | 횭 | 횮 | 횯 |
| 0xd6b | 횰 | 횱 | 횲 | 횳 | 횴 | 횵 | 횶 | 횷 | 횸 | 횹 | 횺 | 횻 | 횼 | 횽 | 횾 | 횿 |
| 0xd6c | 훀 | 훁 | 훂 | 훃 | 후 | 훅 | 훆 | 훇 | 훈 | 훉 | 훊 | 훋 | 훌 | 훍 | 훎 | 훏 |
| 0xd6d | 훐 | 훑 | 훒 | 훓 | 훔 | 훕 | 훖 | 훗 | 훘 | 훙 | 훚 | 훛 | 훜 | 훝 | 훞 | 훟 |
| 0xd6e | 훠 | 훡 | 훢 | 훣 | 훤 | 훥 | 훦 | 훧 | 훨 | 훩 | 훪 | 훫 | 훬 | 훭 | 훮 | 훯 |
| 0xd6f | 훰 | 훱 | 훲 | 훳 | 훴 | 훵 | 훶 | 훷 | 훸 | 훹 | 훺 | 훻 | 훼 | 훽 | 훾 | 훿 |
| 0xd70 | 휀 | 휁 | 휂 | 휃 | 휄 | 휅 | 휆 | 휇 | 휈 | 휉 | 휊 | 휋 | 휌 | 휍 | 휎 | 휏 |
| 0xd71 | 휐 | 휑 | 휒 | 휓 | 휔 | 휕 | 휖 | 휗 | 휘 | 휙 | 휚 | 휛 | 휜 | 휝 | 휞 | 휟 |
| 0xd72 | 휠 | 휡 | 휢 | 휣 | 휤 | 휥 | 휦 | 휧 | 휨 | 휩 | 휪 | 휫 | 휬 | 휭 | 휮 | 휯 |
| 0xd73 | 휰 | 휱 | 휲 | 휳 | 휴 | 휵 | 휶 | 휷 | 휸 | 휹 | 휺 | 휻 | 휼 | 휽 | 휾 | 휿 |
| 0xd74 | 흀 | 흁 | 흂 | 흃 | 흄 | 흅 | 흆 | 흇 | 흈 | 흉 | 흊 | 흋 | 흌 | 흍 | 흎 | 흏 |
| 0xd75 | 흐 | 흑 | 흒 | 흓 | 흔 | 흕 | 흖 | 흗 | 흘 | 흙 | 흚 | 흛 | 흜 | 흝 | 흞 | 흟 |
| 0xd76 | 흠 | 흡 | 흢 | 흣 | 흤 | 흥 | 흦 | 흧 | 흨 | 흩 | 흪 | 흫 | 희 | 흭 | 흮 | 흯 |
| 0xd77 | 흰 | 흱 | 흲 | 흳 | 흴 | 흵 | 흶 | 흷 | 흸 | 흹 | 흺 | 흻 | 흼 | 흽 | 흾 | 흿 |
| 0xd78 | 힀 | 힁 | 힂 | 힃 | 힄 | 힅 | 힆 | 힇 | 히 | 힉 | 힊 | 힋 | 힌 | 힍 | 힎 | 힏 |
| 0xd79 | 힐 | 힑 | 힒 | 힓 | 힔 | 힕 | 힖 | 힗 | 힘 | 힙 | 힚 | 힛 | 힜 | 힝 | 힞 | 힟 |
| 0xd7a | 힠 | 힡 | 힢 | 힣 | | | | | | | | | | | | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xd7b | ힰ | ힱ | ힲ | ힳ | ힴ | ힵ | ힶ | ힷ | ힸ | ힹ | ힺ | ힻ | ힼ | ힽ | ힾ | ힿ |
| 0xd7c | ퟀ | ퟁ | ퟂ | ퟃ | ퟄ | ퟅ | ퟆ | | | | | ퟋ | ퟌ | ퟍ | ퟎ | ퟏ |
| 0xd7d | ퟐ | ퟑ | ퟒ | ퟓ | ퟔ | ퟕ | ퟖ | ퟗ | ퟘ | ퟙ | ퟚ | ퟛ | ퟜ | ퟝ | ퟞ | ퟟ |
| 0xd7e | ퟠ | ퟡ | ퟢ | ퟣ | ퟤ | ퟥ | ퟦ | ퟧ | ퟨ | ퟩ | ퟪ | ퟫ | ퟬ | ퟭ | ퟮ | ퟯ |
| 0xd7f | ퟰ | ퟱ | ퟲ | ퟳ | ퟴ | ퟵ | ퟶ | ퟷ | ퟸ | ퟹ | ퟺ | ퟻ | | | | |
코덱
코덱(codec)은 순수 데이터(row data)를 가공하는 기술로, 문자열 코덱, 이미지 코덱, 동영상 코덱, 압축 코덱 등이 존재합니다.
- row data: 처리전 순수 데이터(암호학: 평서문(plain text))
- encoding: 처리(캡슐화, 압축, 암호화) 과정
- encapsulated data: 가공된 데이터(암호학: 암호문(ciphertext))
- decoding: 역처리(데이터 추출, 압축해제, 복호화) 과정
문자열 코덱의 이유는 코드북(예: ascii, unicode)의 확장 가능성이나 선별 등의 이유로 설계됩니다. 컴퓨터가 숫자를 만났을 때, 바로 코드북과 비교하는 것이 아니라, 어떤 코덱으로 디코딩을 수행 한 뒤, 결과물을 코드북에서 찾아서 출력하게 됩니다.
EUC-KR
2 byte의 정보에 코덱 정보를 넣어 2 byte정보를 넣을 수는 없습니다. 따라서 EUC-KR은 사용하지 않을 것 같은 글자(2,350자)를 빼고, 8,822글자만 표현하게 됩니다. 다음은 C코드로 숫자를 생성 한 뒤, 윈도우 전용 터미널을 통해서 출력한 결과입니다.
char p = 0xb0;
char q = 0xa1;
for (int i = 0; i < 20; i++) {
printf("%02X%02X : ", p & 0xFF, q & 0xFF);
for (int j = 0; j < 16; j++) {
printf("%c%c ", p, q++);
if (!q) {
p++;
q = 0xA0;
}
}
printf("\n");
}B0A1 : 가 각 간 갇 갈 갉 갊 감 갑 값 갓 갔 강 갖 갗 같 B0B1 : 갚 갛 개 객 갠 갤 갬 갭 갯 갰 갱 갸 갹 갼 걀 걋 B0C1 : 걍 걔 걘 걜 거 걱 건 걷 걸 걺 검 겁 것 겄 겅 겆 B0D1 : 겉 겊 겋 게 겐 겔 겜 겝 겟 겠 겡 겨 격 겪 견 겯 B0E1 : 결 겸 겹 겻 겼 경 곁 계 곈 곌 곕 곗 고 곡 곤 곧 B0F1 : 골 곪 곬 곯 곰 곱 곳 공 곶 과 곽 관 괄 괆 ? 콬 B1A1 : 괌 괍 괏 광 괘 괜 괠 괩 괬 괭 괴 괵 괸 괼 굄 굅 B1B1 : 굇 굉 교 굔 굘 굡 굣 구 국 군 굳 굴 굵 굶 굻 굼 B1C1 : 굽 굿 궁 궂 궈 궉 권 궐 궜 궝 궤 궷 귀 귁 귄 귈 B1D1 : 귐 귑 귓 규 균 귤 그 극 근 귿 글 긁 금 급 긋 긍 B1E1 : 긔 기 긱 긴 긷 길 긺 김 깁 깃 깅 깆 깊 까 깍 깎 B1F1 : 깐 깔 깖 깜 깝 깟 깠 깡 깥 깨 깩 깬 깰 깸 ? 쿋 B2A1 : 깹 깻 깼 깽 꺄 꺅 꺌 꺼 꺽 꺾 껀 껄 껌 껍 껏 껐 B2B1 : 껑 께 껙 껜 껨 껫 껭 껴 껸 껼 꼇 꼈 꼍 꼐 꼬 꼭 B2C1 : 꼰 꼲 꼴 꼼 꼽 꼿 꽁 꽂 꽃 꽈 꽉 꽐 꽜 꽝 꽤 꽥 B2D1 : 꽹 꾀 꾄 꾈 꾐 꾑 꾕 꾜 꾸 꾹 꾼 꿀 꿇 꿈 꿉 꿋 B2E1 : 꿍 꿎 꿔 꿜 꿨 꿩 꿰 꿱 꿴 꿸 뀀 뀁 뀄 뀌 뀐 뀔 B2F1 : 뀜 뀝 뀨 끄 끅 끈 끊 끌 끎 끓 끔 끕 끗 끙 ? 퀬 B3A1 : 끝 끼 끽 낀 낄 낌 낍 낏 낑 나 낙 낚 난 낟 날 낡 B3B1 : 낢 남 납 낫 났 낭 낮 낯 낱 낳 내 낵 낸 낼 냄 냅
EUC-KR의 이러한 결정은 훗날 '아헤헿', '뷁' 등 표현 할 수 없는 문자들로 인해 고통받게 됩니다. 실제로 이러한 단어들의 코드를 출력해보면, '갂', '갃'등의 코드범위가 다름을 확인 할 수 있습니다.
char hangle[31] = "가각갂갃간개객갞갟갠까깍깎깏깐";
printf("%s\n", hangle);
for (int i = 0; i < 30; i++) {
printf("%02X ", * (hangle + i) & 0xFF);
if (i % 2)
printf(" / ");
if (!((i+1) % 10))
printf("\n");
}
char16_t c = 0xAC00;
printf("%s\n", (char *) & c);가각갂갃간개객갞갟갠까깍깎깏깐 B0 A1 / B0 A2 / 81 41 / 81 42 / B0 A3 / B0 B3 / B0 B4 / 81 4B / 81 4C / B0 B5 / B1 EE / B1 EF / B1 F0 / 83 8A / B1 F1 /
Unicode출력
C코드에서 출력하는 방법
//EUC-KR : 각(B0A2 : 1011 0000 1010 0010)
//유니코드 : 각(AC01 : 1010 1100 0000 0001)
char16_t c[5] = { 0xA2B0, 0x4181, 0x4281, 0xA3B0, 0 };
printf("EUC-KR : %s\n", (char*)&c);
char str[10] = "\uac01\uac02\uac03\uac04";
printf("Uni-Code : %s\n", str);EUC-KR : 각갂갃간 Uni-Code : 각갂갃간
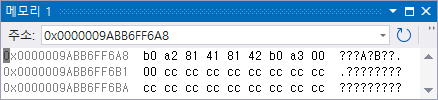 각갂갃간의 실제 메모리 로드
"euckr_memory.png", @iseohyun.com, ⓒpublic
각갂갃간의 실제 메모리 로드
"euckr_memory.png", @iseohyun.com, ⓒpublic
웹에서 유니코드 표현하는 방법
특수문자는 '&[#숫자 또는 예약어];'형식입니다. 예를들어, 띄어쓰기는 거나   또는  (160은 16진수로 'A0'이다)로 표현 할 수 있습니다. 같은 원리로 '가'를 출력하기 위해서는 가을 입력하면 됩니다.
예약어에 대한 자세한 설명은 여기를 참고하십시오.
직접 코드페이지를 작성하고 싶다면 아래 python코드가 도움이 될지 모릅니다.
start = 0x1100
end = 0x11FF
cur = start
file = "out.txt"
with open(file, "w+", encoding="utf8") as f:
for i in range((end - start) // 16 + 1):
f.write(f"\n0x{cur//16:x} ")
for i in range(16):
f.write(f"&#x{cur:x}; ")
cur += 1
결론
UTF-8 씁시다.